As you probably know from my previous posts, my colleagues at paiqo.com and I are constantly working to improve our VSCode extension for Databricks. Almost every month we silently release a new version to the VSCode gallery so you get the latest features. However, as this is a special release, I am also writing a dedicated blog post for it
We are very happy to finally announce the first official release of our VSCode extension for Databricks!
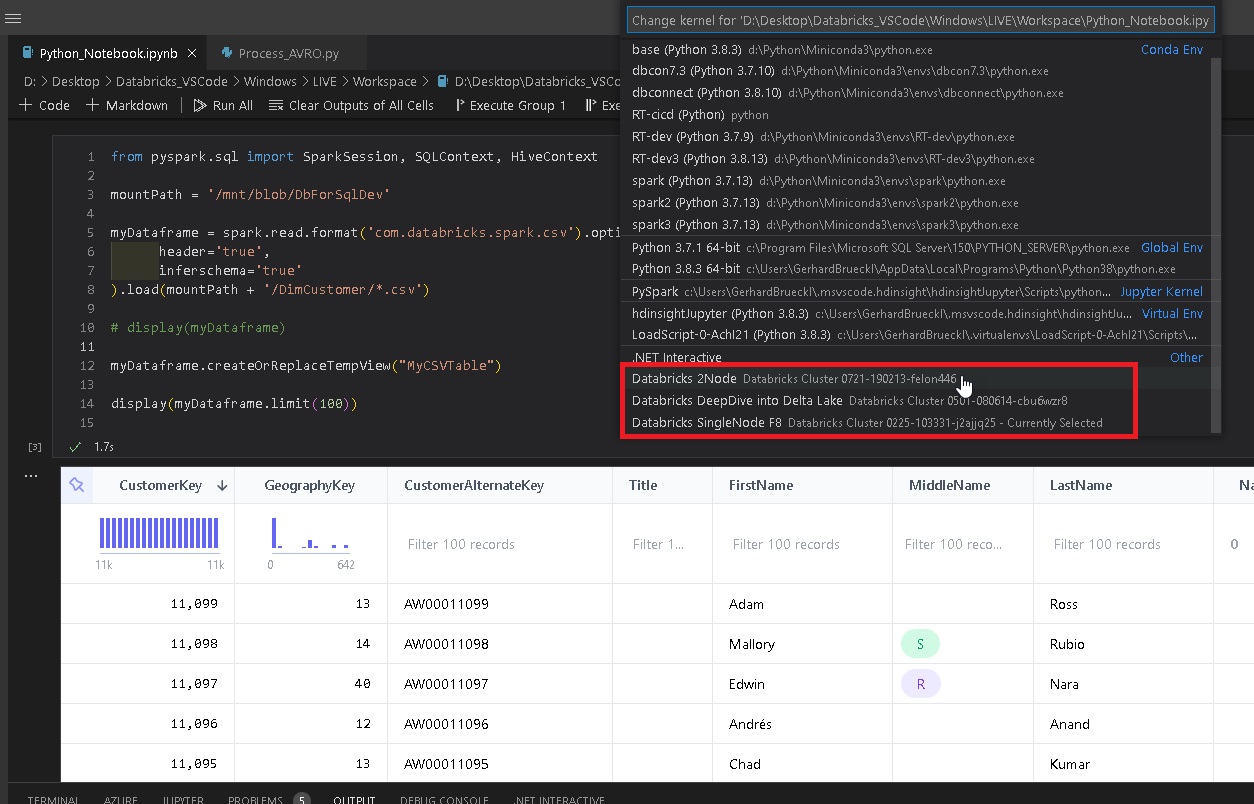
Probably the biggest and most awaited new feature is the ability to interactively execute your local Spark/SQL/Scala/R code against one of your running Databricks clusters and get the results back in VSCode! At least every 3rd issue that was opened in our Github Repo was requesting this feature and now it is finally here. It integrates seamlessly into VSCode notebooks by automatically creating a new kernel for every active Databricks cluster in your workspace. So just open one of your notebook, select the Databricks cluster kernel and start working!
Integrating it natively with VSCode notebooks brings some very nice features out of the box:
leverages all other extensions that work with Python or notebooks: syntax highlighting, auto-completion, colored indention levels (e.g using indent-rainbow)
In addition to all the features already mentioned above, it also solves some issues that you may had with other solutions like databricks-connect (which is also deprecated by now). The following things also work with the new Databricks VSCode notebook kernel:
full access to the DBFS including mountpoints
most dbutils functions like dbutils.secrets
magics like %pip, %md and all language-specific magics
However, besides all those great new features and capabilities, there are also some things that still need improvement. Here is a list of known issues:
widgets are currently not supported – that’s our highest priority at the moment
found any other issues? report them at at issues-page
All further details can be found in the README.md of the Github repository.
Let us know what you think of and provide some feedback! If you already had an older version of the extension installed, it will update automatically. If you have not used it yet, just install it directly via the VSCode extensions or download it from the VSCode gallery or our GitHub repository:
I also contributed the connector described in this post to the official delta.io Connectors page and repo (link). You will find the most recent updates in my personal repo which are then merged to the official repo once it has been tested thoroughly!
Working with analytical data platforms and big data on a daily basis, I was quite happy when Microsoft finally announced a connector for Parquet files back in November 2020. The Parquet file format is developed by the Apache foundation as an open-source project and has become a fundamental part of most data lake systems nowadays.
“Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.”
However, Parquet is just a file format and does not really support you when it comes to data management. Common data manipulation operations (DML) like updates and deletes still need to be handled manually by the data pipeline. This was one of the reasons why Delta Lake (delta.io) was developed besides a lot of other features like ACID transactions, proper meta data handling and a lot more. If you are interested in the details, please follow the link above.
So what is a Delta Lake table and how is it related to Parquet? Basically a Delta Lake table is a folder in your Data Lake (or wherever you store your data) and consists of two parts:
Delta log files (in the sub-folder _delta_log)
Data files (Parquet files in the root folder or sub-folders if partitioning is used)
The Delta log persists all transactions that modified the data or meta data in the table. For example, if you execute an INSERT statement, a new transaction is created in the Delta log and a new file is added to the data files which is referenced by the Delta log. If a DELETE statement is executed, a particular set of data files is (logically) removed from the Delta log but the data file still resides in the folder for a certain time. So we cannot just simply read all Parquet files in the root folder but need to process the Delta log first so we know which Parquet files are valid for the latest state of the table.
These logs are usually stored as JSON files (actually JSONL files to be more precise). After 10 transactions, a so-called checkpoint-file is created which is in Parquet format and stores all transactions up to that point in time. The relevant logs for the final table are then the combination of the last checkpoint-file and the JSON files that were created afterwards. If you are interested in all the details on how the Delta Log works, here is the full Delta Log protocol specification.
From those logs we get the information which Parquet files in the main folder must be processed to obtain the final table. The content of those Parquet files can then simply be combined and loaded into PowerBI.
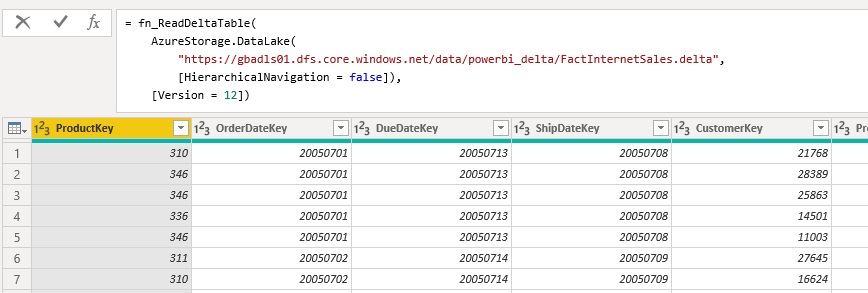
I encapsulated all this logic into a custom Power Query function which takes the folder listing of the Delta table folder as input and returns the content of the Delta table. The folder listing can either come from an Azure Data Lake Store, a local folder, or an Azure Blob Storage. The mandatory fields/columns are [Content], [Name] and [Folder Path]. There is also an optional parameter which allows you the specify further options for reading the Delta table like the Version if you want to use time-travel. However, this is still experimental and if you want to get the latest state of the table, you can simply omit it.
The most current M-code for the function can be found in my Github repository for PowerBI: fn_ReadDeltaTable.pq and will also be constantly updated there if I find any improvement. The repository also contains an PowerBI desktop file (.pbix) where you can see the single steps that make up for the final function.
Once you have added the function to your PowerBI / Power Query environment you can call it like this:
I would further recommend to nest your queries and separate the access to the storage (e.g. Azure Data Lake Store) and the reading of the table (execution of the function). If you are reading for an ADLS, it is mandatory to also specify [HierarchicalNavigation = false] ! If you are reading from a blob storage, the standard folder listing is slightly different and needs to be changed.
Right now the connector/function is still experimental and performance is not yet optimal. But I hope to get this fixed in the near future to have a native way to read and finally visualize Delta lake tables in PowerBI.
After some thorough testing the connector/function finally reached a state where it can be used without any major blocking issues, however there are still some known limitations:
Partitioned tables
currently columns used for partitioning will always have the value NULLFIXED!
values for partitioning columns are not stored as part of the parquet file but need to be derived from the folder pathFIXED!
Performance
is currently not great but this is mainly related to the Parquet connector as it seems
very much depends on your data – please test on your own!
Time Travel
currently only supports “VERSION AS OF”
need to add “TIMESTAMP AS OF”
Predicate Pushdown / Partition Elimination
currently not supported – it always reads the whole tableFIXED!
Any feedback is welcome!
Special thanks also goes to Imke Feldmann (@TheBIccountant, blog) and Chris Webb (@cwebb_bi, blog) who helped me writing and tuning the PQ function!
Calculating and visualizing semi- and non-additive measures like distinct count in Power BI is usually not a big deal. However, things can become challenging if your data volume grows and exceeds the limits of Power BI!
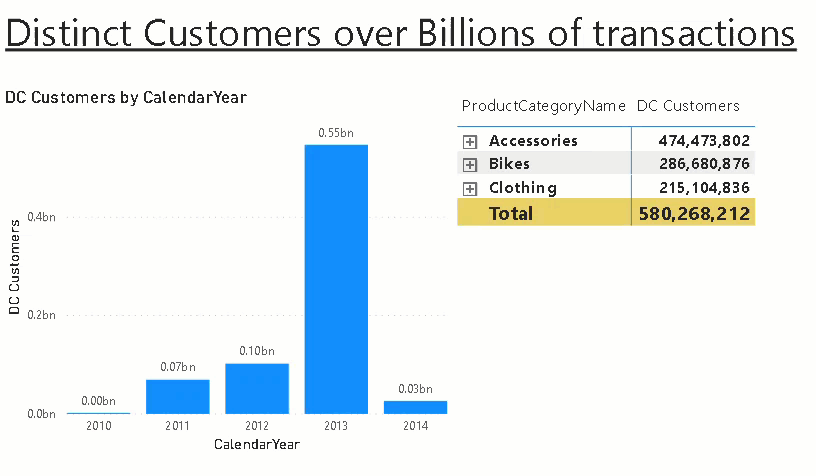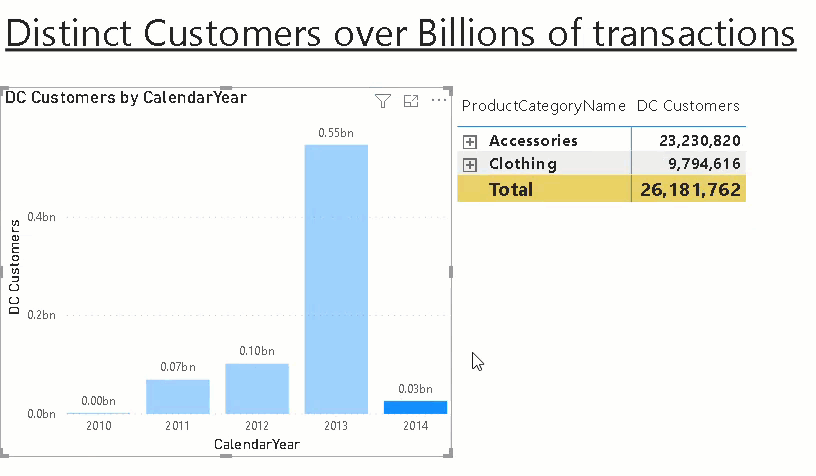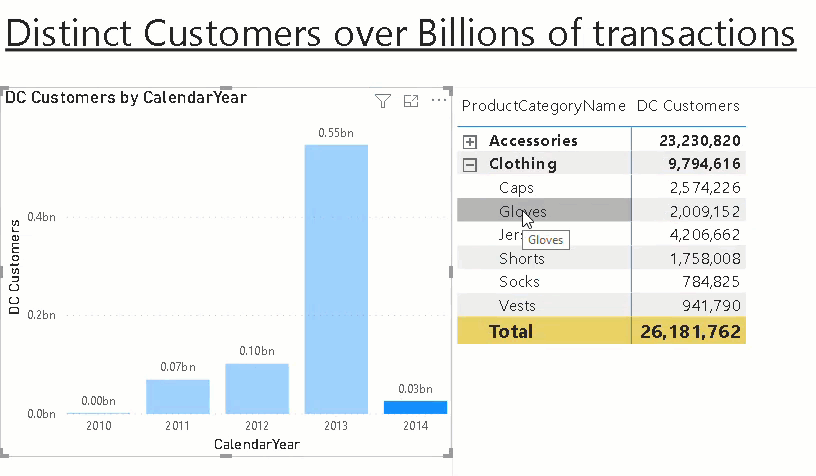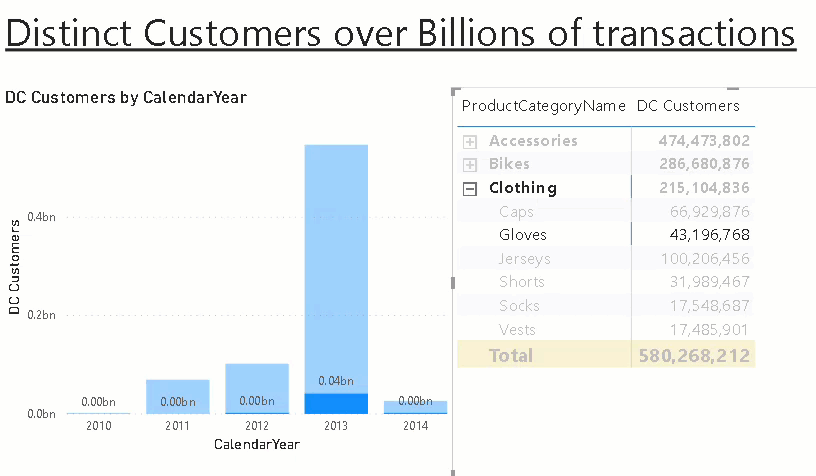
In one of my recent projects we wanted to visualize data from the customers analytical platform based on Azure Databricks in Power BI. The connection between those two tools works pretty flawless which I also described in my previous post but the challenge was the use-case and the calculations. We wanted to display the distinct customers across various aggregations levels over a billion rows fact table. We came up with different potential solutions all having their pros and cons:
load all data into Power BI (import mode) and do the aggregations there
use Power BI with direct query and let the back-end do the heavy lifting
load only necessary pre-aggregated data into Power BI (import mode)
Please keep in mind that we are dealing with a distinct count measure here. Semi- and Non-additive measure like this cannot easily be aggregated from lower levels to higher levels without having all the detail data available!
Option 1. has the obvious drawback that data model would be huge in size as we were dealing with billions of transactions. This would have exceeded our current size limits for Power BI data models.
Option 2. would usually work fine, but again, for the amount of data we were dealing with the back-end was just no able to provide sub-second latency that was required.
So we went for Option 3. and did the various aggregations on the different levels in Azure Databricks and loaded only the final results to Power BI. First we wanted to use Power BI Aggregations and Composite Models. Unfortunately, this did not work out for us as we were not in control which aggregation table (we had multiple for the different aggregation levels) was used by the engine which potentially resulted in wrong results when additional aggregation was done in Power BI. Also, when slicing for random aggregation levels, Power BI was querying the details in direct query mode causing very poor query performance.
After some further thinking we came up with a new solution which was also based on pre-calculated aggregations but not realized using built-in aggregation tables but having a combined table for all aggregations and some very straight-forward DAX to select the row we wanted! In the end the whole solution consisted of one SQL view using COUNT(DISTINCT xxx) aggregation and GROUP BY GROUPING SETS (T-SQL, Databricks, … supported in all major SQL engines) and a very simple DAX measure!
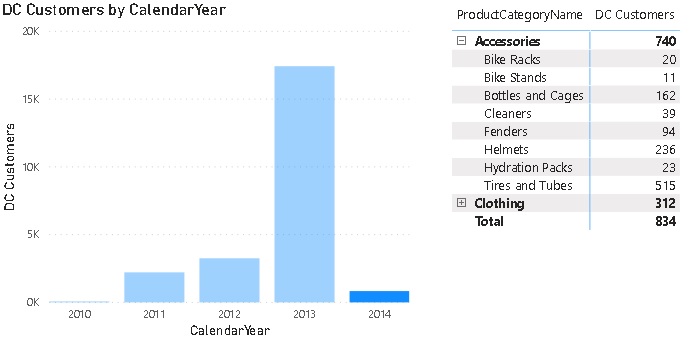
Here is a little example that illustrates the approach. Assume you want to calculate the distinct customers that bought certain products in a subcategory/category by year. The first step is to create a view that provides this information:
Default
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
SELECT
od.[CalendarYear] AS [Year],
dp.[ProductSubcategoryKey] AS [ProductSubcategoryKey],
Please note that when we have a natural relationship between hierarchy levels (= only 1:n relationships) we need to specify the current level and also all upper levels to allow a proper drill-down later on! E.g. ProductCategory (1 -> n) ProductSubcategory
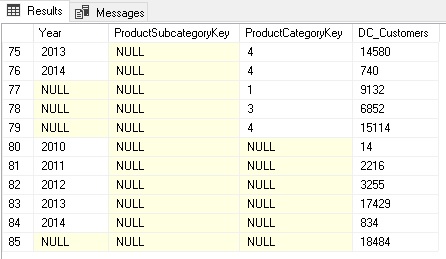
This calculates all the different aggregation levels we need. Columns with NULL mean they were not filtered/grouped by when calculating the aggregation. Rows 80-84 contain the aggregations grouped by Year only whereas rows 77-79 contain only aggregates by ProductCategoryKey. The rows 75-76 were aggregated by Year AND ProductCategoryKey. Depending on your final report layout, you may not need all of them and you should consider removing those that are not needed!
This table is then loaded into Power BI. You can either use a custom SQL query like above in Power BI directly or create a view in the back-end system which would be my preferred solution. Alternatively you can also create all these grouping sets using Power Query/M. The incredible Imke Feldmann (t, b) came up with a solution that allows you to specify the grouping sets in a similar way as in SQL and do all this magic within Power BI directly! I hope she will blog about it pretty soon! (The sample workbook at the end of this post also contains a little preview of this M-magic.)
Now that we have all the data we need in Power BI, we need to display the right values for the selections in the report which of course can be dynamic. That’s a bit tricky but once you understand the concept, it is pretty straight forward. First of all, the table containing the aggregations must not be related to any other table as we build them on the fly within our DAX measure. The table itself can also be hidden.
And this is the final DAX for our measure:
Default
1
2
3
4
5
6
7
8
9
10
11
12
13
DC Customers =
VAR _sel_SubcategoryKey = SELECTEDVALUE(DimProduct[ProductSubcategoryKey])
VAR _sel_CategoryKey = SELECTEDVALUE(DimProduct[ProductCategoryKey])
VAR _sel_Year = SELECTEDVALUE(DimDate[CalendarYear])
The first part is to get all the selected values of the lookup/dimension tables the user selects on the report. These are all the _sel_XXX variables. SELECTEDVALUE() returns the selected value if only one item is in the current filter context and BLANK()/NULL otherwise. We then use TREATAS() to apply those filters (either a single item or NULL) to our aggregations table. This should usually only return a table with a single row so we can use MAXX() to get our actual value from that one row. I also added a check in case multiple rows are returned which can potentially happen if you use multi-selects in your filters and instead of showing wrong values I’d rather indicate that there is something wrong with the calculation.
The measure can then be sliced and diced by our pre-defined aggregation levels as if it would be a regular measure but instead of having to process those expensive calculations on the fly we use the pre-calculated aggregates!
One thing to be aware of is that it will produce wrong results if multiple items for any of the aggregation levels are selected so it is highly recommended to set all slicers/filters to single select only or ensure that the filtered aggregation levels are also used in the chart. In this case only the grand total will show wrong values or NULL then. This could also be fixed in the DAX measure by checking how many rows are actually selected for each level and throw an error in case it is used in a filter and the count of values is > 1.
I did some further thinking and this approach could probably also be used to mimic custom roll-ups and unary operators we know from Analysis Services Multidimensional cubes. If I find some proper examples and this turns out to be feasibly I will write another blog post about it!
I work a lot with Azure Databricks and a topic that always comes up is reporting on top of the data that is processed with Databricks. Even though notebooks offer some great ways to visualize data for analysts and power users, it is usually not the kind of report the top-management would expect. For those scenarios, you still need to use a proper reporting tool, which usually is Power BI when you are already using Azure and other Microsoft tools.
So, I am very happy that there is finally an official connector in PowerBI to access data from Azure Databricks! Previously you had to use the generic Spark connector (docs) which was rather difficult to configure and did only support authentication using a Databricks Personal Access Token.
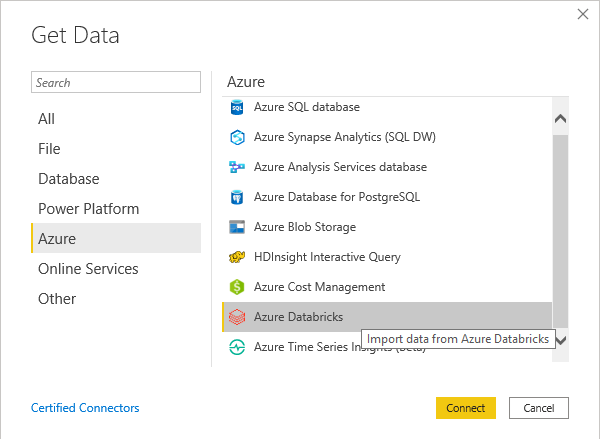
With the new connector you can simply click on “Get Data” and then either search for “Azure Databricks” or go the “Azure” and scroll down until you see the new connector:
The next dialog that pops up will ask you for the hostname and HTTP path – this is very similar to the Spark connector. You find all the necessary information via the Databricks Web UI. As this connection is always bound to an existing cluster you need to go the clusters details page and check the Advanced Tab “JDBC/ODBC” as described here: (NOTE: you can simply copy the Server Hostname and the HTTP Path from the cluster page)
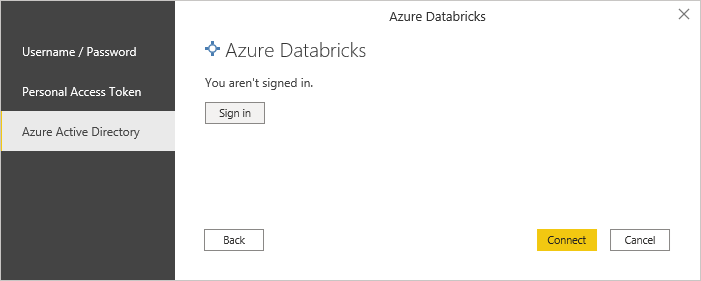
The last part is then the authentication. As mentioned earlier the new connector now also supports Azure Active Directory authentication which allows you to use the same user that you use to connect to the Databricks Web UI! Personal Access Tokens are also still supported and there is also Basic authentication using username/password.
Once you are connected, you can choose the tables that you want to import/connect and start building your report!
Here is also a quick overview which features are supported by the Spark and the Azure Databricks connector as there are some minor but important differences:
Feature Comparison
Spark Connector
Databricks Connector
Power BI Desktop
YES
YES
Power BI Service
YES
YES *
Direct Query (Desktop)
YES
YES
Direct Query (Service)
YES
YES *
Import Mode
YES
YES
Manual Refresh (Service)
YES
YES *
Scheduled Refresh (Service)
YES
YES *
Azure Active Directory (AAD) Authentication
NO
YES
Personal Access Token Authentication
YES
YES
Username/Password Authentication
YES
YES
General Available
YES
YES
Performacne Improvements with Spark 3.x
NO *
YES *
Supports On-Premises data gateway
YES
NO
Features supported by Spark and Databricks Connector for PowerBI
*) Updated 2020-10-06: the new Databricks Connector for PowerBI now supports all features also in the PowerBI service!
Update 2020-10-06: So from the current point of view the new Databricks Connector is a superset of old Spark Connector with additional options for authentication and better performance with the latest Spark versions. So it is highly recommended to use the new Databricks Connector unless you have very specific reasons to use the Spark connector! Actually the only reason why I would still use the Spark connector is the support for the On-Premises data gateway in case your Spark or Databricks cluster is hosted in a private VNet.
So currently the generic Spark connector still looks superior simply for the support in the Power BI Service. However, I am quite sure that it will be fully supported also by the Power BI Service in the near future. I will update this post accordingly! On the other hand, Azure Active Directory authentication is a huge plus for the native Azure Databricks connector as you do not have to mess around with Databricks Personal Access Tokens (PAT) anymore!
Another thing that I have not yet tested but would be very interesting is whether Pass-Through security works with this new connector. So you log in with your AAD credentials in Power BI, they get passed on to Databricks and from there to the Data Lake Store. For Databricks Table Access Control I assume this will just work as it does for PAT as it is not related to AAD authentication.
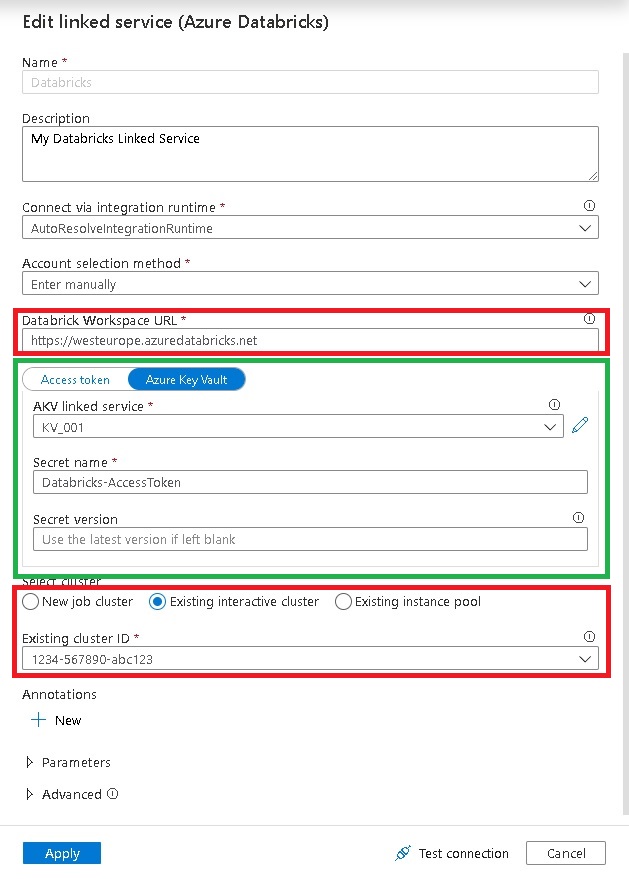
Paul Andrews (b, t) recently blogged about HOW TO USE ‘SPECIFY DYNAMIC CONTENTS IN JSON FORMAT’ IN AZURE DATA FACTORY LINKED SERVICES. He shows how you can modify the JSON of a given Azure Data Factory linked service and inject parameters into settings which do not support dynamic content in the GUI. What he shows with Linked Services and parameters also applies to Key Vault references – sometimes the GUI allows you to reference a value from the Key Vault instead of hard-coding it but for other settings the GUI only offers a simple text box:
As You can see, the setting “AccessToken” can use a Key Vault reference whereas settings like “Databricks Workspace URL” and “Cluster” do not support them. This is usually fine because the guys at Microsoft also thought about this and support Key Vault references for the settings that are actually security relevant or sensitive. Also, providing the option to use Key Vault references everywhere would flood the GUI. So this is just fine.
But there can be good reasons where you want to get values from the Key Vault also for non-sensitive settings, especially when it comes to CI/CD and multiple environments. From my experience, when you implement a bigger ADF project, you will probably have a Key Vault for your sensitive settings and all other values are provided during the deployment via ARM parameters.
So you will end up with a mix of Key Vault references and ARM template parameters which very likely will be derived from the Key Vault at some point anyway. To solve this, you can modify the JSON of an ADF linked service directly and inject KeyVault references into almost every property! Lets have a look at the JSON of the Databricks linked service from above:
As you can see in lines 8-15, the property “accessToken” references the secret “Databricks-Accesstoken” from the Key Vault linked service “KV_001” and the actual value is populated at runtime.
After reading all this, you can probably guess what we are going to do next – We also replace the other properties by Key Vault references:
Default
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
{
"name": "Databricks",
"properties": {
"type": "AzureDatabricks",
"annotations": [],
"typeProperties": {
"domain": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "KV_001",
"type": "LinkedServiceReference"
},
"secretName": "Databricks-Workspace-URL"
},
"accessToken": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "KV_001",
"type": "LinkedServiceReference"
},
"secretName": "Databricks-AccessToken"
},
"existingClusterId": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "KV_001",
"type": "LinkedServiceReference"
},
"secretName": "Databricks-ClusterID"
}
}
}
}
You now have a linked service that is configured solely by the Key Vault. If you think one step further, you can replace all values which are usually sourced by ARM parameters with Key Vault references instead and you will end up with an ARM template that only has two parameters – the name of the Data Factory and the URI of the Key Vault linked service! (you may even be able to derive the Key Vaults URI from the Data Factory name if the names are aligned!)
The only drawback I could find so far was that you cannot use the GUI anymore but need to work with the JSON from now on – or at least until you remove the Key Vault references again so that the GUI can display the JSON properly again. But this is just a minor thing as linked services usually do not change very often.
I also tried using the same approach to inject Key Vault references into Pipelines and Dataset but unfortunately this did not work 🙁 This is probably because Pipelines and Datasets are evaluated at a different stage and hence cannot dynamically reference the Key Vault.
Databricks recently announced that it is now also supporting Azure Active Directory Authentication for the REST API which is now in public preview. This may not sound super exciting but is actually a very important feature when it comes to Continuous Integration/Continuous Delivery pipelines in Azure DevOps or any other CI/CD tool. Previously, whenever you wanted to deploy content to a new Databricks workspace, you first needed to manually create a user-bound API access token. As you can imagine, manual steps are also bad for otherwise automated processes like a CI/CD pipeline. With Databricks REST API finally supporting Azure Active Directory Authentication of regular users and service principals, this last manual step is finally also gone!
As I had this issue at many of my customers where we had already fully automated the deployment of our data platform based on Azure and Databricks, I also wanted to use this new feature there. The deployment of regular Databricks objects (clusters, notebooks, jobs, …) was already implemented in the CI/CD pipeline using my PowerShell module DatabricksPS and of course I did not want to rewrite any of those steps. So, I simply extend the module’s authentication methods to also support Azure Active Directory Authentication. The only thing that actually changed was the call to Set-DatabricksEnvironment which now supports additional parameter sets and parameters:
The first thing you will realize is that it is now necessary to specify the Databricks Workspace explicitly either using SubscriptionID/ResourceGroupName/WorkspaceName to uniquely identify the Databricks workspace within Azure or using the OrganizationID that you see displayed in the URL of your Databricks Workspace. For the actual authentication the parameters -ClientID, -TenantID, -Credential and the switch -ServicePrincipal are used.
Regardless of whether you use regular username/password authentication with an AAD user or an AAD service principal, the first thing you need to do in both cases is to create an AAD Application as described in the official docs from Databricks: Using Azure Active Directory Authentication Library Using a service principal
Once you have ensured all prerequisites exist, you can use the samples below to authenticate with your AAD username/password with DatabricksPS:
As you can see, once the environment is set up using the new authentication methods, the rest of the script stays the same and there is not much more you need to do fully automate your CI/CD pipeline with DatabricksPS!
I have not yet fully tested all cmdlets of the module so if you experience any issues, please contact me or open a ticket in the GIT repository.
When working with Databricks you will usually start developing your code in the notebook-style UI that comes natively with Databricks. This is perfectly fine for most of the use cases but sometimes it is just not enough. Especially nowadays, where a lot of data engineers and scientists have a strong background also in regular software development and expect the same features that they are used to from their original Integrated Development Environments (IDE) also in Databricks.
For those users Databricks has developed Databricks Connect (Azure docs) which allows you to work with your local IDE of choice (Jupyter, PyCharm, RStudio, IntelliJ, Eclipse or Visual Studio Code) but execute the code on a Databricks cluster. This is awesome and provides a lot of advantages compared to the standard notebook UI. The two most important ones are probably the proper integration into source control / git and the ability to extend your IDE with tools like automatic formatters, linters, custom syntax highlighting, …
While Databricks Connect solves the problem of local execution and debugging, there was still a gap when it came to pushing your local changes back to Databricks to be executed as part of a regular ETL or ML pipeline. So far you had to either “deploy” your changes by manually uploading them via the Databricks UI again or write a script that uploads it via the REST API (Azure docs).
NOTE: I also published a PowerShell module that eases the automation/scripting of these tasks also as part of CI/CD pipeline. It is available from the PowerShell gallery DatabricksPS and integrates very well with this VSCode extension too!
However, this is not really something you would call a “seamless experience” so I also started working on an extension for Visual Studio Code to work more efficiently with Databricks. It has been in the VS Code gallery (Databricks VSCode) for about a month now and I received mostly positive feedback so far. Now I am at a stage where I want to get more people to use it – hence this blog post to announce it officially. The extension is currently published under GPLv3 license and is free to use for everyone. The GIT repository is also linked in the VS Code gallery if you want to participate or have any issues with the extension.
It currently supports the following features:
Workspace browser
Up-/download of notebooks and whole folders
Compare/Diff of local vs online notebook (currently only supported for raw files but not for notebooks)
Execution of local code and notebooks against a Databricks Cluster (via Databricks-Connect)
Cluster manager
Start/stop clusters
Script cluster definition as JSON
Job browser
Start/stop jobs
View job-run history + status
Script job definition as JSON
Script job-run output as JSON
DBFS browser
Upload files
Download files
(also works with mount points!)
Secrets browser
Create/delete secret scopes
Create/delete secrets
Support for multiple Databricks workspaces (e.g. DEV/TEST/PROD)
Easy configuration via standard VS Code settings
More features to come in the future but these will be mainly based on the requests that come from users or my personal needs. So your feedback is highly appreciated – either directly here or using the feedback section in the GIT repository.
I will also write some follow up post to show you how to work in the most efficient way using this new VSCode extension in combination with your Databricks workspace so stay tuned!
Foreword: The approach described in this blog post only uses the Databricks REST API and therefore should work with both, Azure Databricks and also Databricks on AWS!
It recently had to migrate an existing Databricks workspace to a new Azure subscription causing as little interruption as possible and not loosing any valuable content. So I thought a simple Move of the Azure resource would be the easiest thing to do in this case. Unfortunately it turns out that moving an Azure Databricks Service (=workspace) is not supported:
Resource move is not supported for resource types ‘Microsoft.Databricks/workspaces’. (Code: ResourceMoveNotSupported)
I do not know what is/was the problem here but I did not have time to investigate but instead needed to come up with a proper solution in time. So I had a look what needs to be done for a manual export. Basically there are 5 types of content within a Databricks workspace:
Workspace items (notebooks and folders)
Clusters
Jobs
Secrets
Security (users and groups)
For all of them an appropriate REST API is provided by Databricks to manage and also exports and imports. This was fantastic news for me as I knew I could use my existing PowerShell module DatabricksPS to do all the stuff without having to re-invent the wheel again. So I basically extended the module and added new Import and Export functions which automatically process all the different content types:
Export-DatabricksEnvironment
Import-DatabricksEnvironment
They can be further parameterized to only import/export certain artifacts and how to deal with updates to already existing items. The actual output of the export looks like this and of course you can also modify it manually to your needs – all files are in JSON except for the notebooks which are exported as .DBC file by default:
A very simple sample code doing and export and an import into a different environment could look like this:
Having those scripts made the whole migration a very easy task. In addition, these new cmdlets can also be used in your Continuous Integration/Continuous Delivery (CI/CD) pipelines in Azure DevOps or any other CI/CD tool!
So just download the latest version from the PowerShell gallery and give it a try!
Over the last year I worked a lot with Databricks on Azure and I have to say that I was (and still am) very impressed how well it works and how it integrates with other services of the Microsoft Azure Data Platform like Data Lake Store, Data Factory, etc.
Some of the projects I worked on also included CI/CD like pipelines using Azure DevOps where Databricks did not really shine so bright in the beginning. There are no native tasks for it or anything. But this is OK as for those scenarios, where you need to automate/script something, Databricks offers a REST API (Azure, AWS).
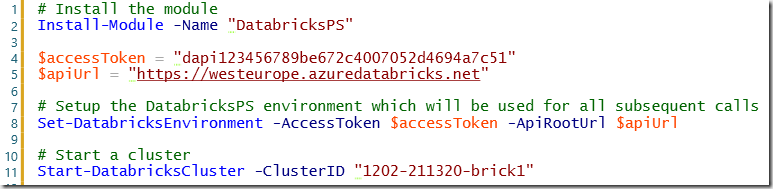
As most of our deployments use PowerShell I wrote some cmdlets to easily work with the Databricks API in my scripts. These included managing clusters (create, start, stop, …), deploying content/notebooks, adding secrets, executing jobs/notebooks, etc. After some time I ended up having 20+ single scripts which was not really maintainable any more. So I packed them into a PowerShell module and also published it to the PowerShell Gallery (https://www.powershellgallery.com/packages/DatabricksPS) for everyone to use!
The module works for Databricks on Azure and also if you run Databricks on AWS – fortunately the API endpoints are almost identical.
The usage is quite simple as for any other PowerShell module:
Install it using Install-Module cmdlet
Setup the Databricks environment using API key and endpoint URL
All the cmdlets are documented and contain links to official documentation of the Rest API call used by the cmdlet. Some API endpoints support different variations of parameters – this was implemented using different parameter sets in PowerShell. There are still some ongoing tests (especially on AWS) and improvements but I general all cmdlets work as expected. I hope this helps anyone else who also has to deal with the Databricks APIs frequently or has to integrate it in a CI/CD pipeline.