I work a lot with Azure Databricks and a topic that always comes up is reporting on top of the data that is processed with Databricks. Even though notebooks offer some great ways to visualize data for analysts and power users, it is usually not the kind of report the top-management would expect. For those scenarios, you still need to use a proper reporting tool, which usually is Power BI when you are already using Azure and other Microsoft tools.
So, I am very happy that there is finally an official connector in PowerBI to access data from Azure Databricks! Previously you had to use the generic Spark connector (docs) which was rather difficult to configure and did only support authentication using a Databricks Personal Access Token.
With the new connector you can simply click on “Get Data” and then either search for “Azure Databricks” or go the “Azure” and scroll down until you see the new connector:
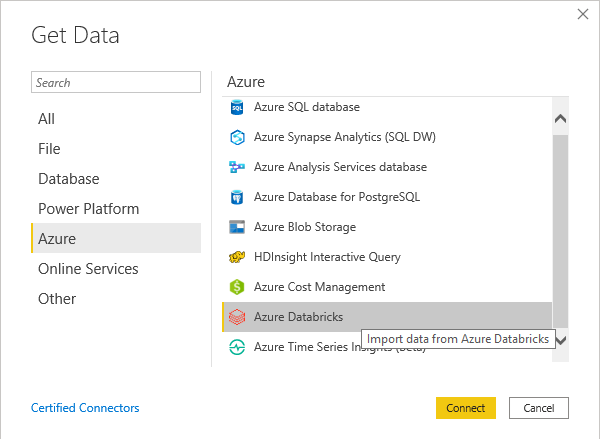
The next dialog that pops up will ask you for the hostname and HTTP path – this is very similar to the Spark connector. You find all the necessary information via the Databricks Web UI. As this connection is always bound to an existing cluster you need to go the clusters details page and check the Advanced Tab “JDBC/ODBC” as described here:
(NOTE: you can simply copy the Server Hostname and the HTTP Path from the cluster page)

The last part is then the authentication. As mentioned earlier the new connector now also supports Azure Active Directory authentication which allows you to use the same user that you use to connect to the Databricks Web UI!
Personal Access Tokens are also still supported and there is also Basic authentication using username/password.
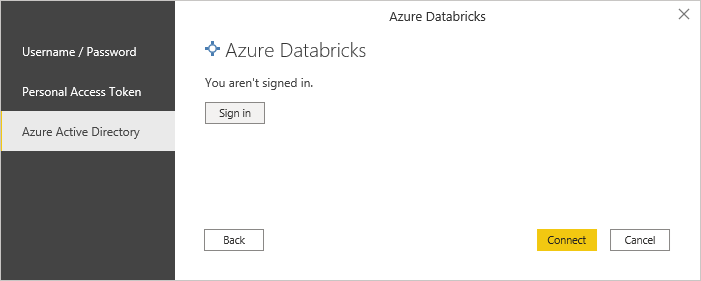
Once you are connected, you can choose the tables that you want to import/connect and start building your report!
Here is also a quick overview which features are supported by the Spark and the Azure Databricks connector as there are some minor but important differences:
| Feature Comparison | Spark Connector | Databricks Connector |
|---|---|---|
| Power BI Desktop | YES | YES |
| Power BI Service | YES | YES * |
| Direct Query (Desktop) | YES | YES |
| Direct Query (Service) | YES | YES * |
| Import Mode | YES | YES |
| Manual Refresh (Service) | YES | YES * |
| Scheduled Refresh (Service) | YES | YES * |
| Azure Active Directory (AAD) Authentication | NO | YES |
| Personal Access Token Authentication | YES | YES |
| Username/Password Authentication | YES | YES |
| General Available | YES | YES |
| Performacne Improvements with Spark 3.x | NO * | YES * |
| Supports On-Premises data gateway | YES | NO |
*) Updated 2020-10-06: the new Databricks Connector for PowerBI now supports all features also in the PowerBI service!
Update 2020-10-06: So from the current point of view the new Databricks Connector is a superset of old Spark Connector with additional options for authentication and better performance with the latest Spark versions. So it is highly recommended to use the new Databricks Connector unless you have very specific reasons to use the Spark connector! Actually the only reason why I would still use the Spark connector is the support for the On-Premises data gateway in case your Spark or Databricks cluster is hosted in a private VNet.
So currently the generic Spark connector still looks superior simply for the support in the Power BI Service. However, I am quite sure that it will be fully supported also by the Power BI Service in the near future. I will update this post accordingly!
On the other hand, Azure Active Directory authentication is a huge plus for the native Azure Databricks connector as you do not have to mess around with Databricks Personal Access Tokens (PAT) anymore!
Another thing that I have not yet tested but would be very interesting is whether Pass-Through security works with this new connector. So you log in with your AAD credentials in Power BI, they get passed on to Databricks and from there to the Data Lake Store. For Databricks Table Access Control I assume this will just work as it does for PAT as it is not related to AAD authentication.
Pingback: PowerBI & Big Data – Using pre-calculated Aggregations of Semi- and Non-Additive Measures | Gerhard Brueckl on BI & Data
Pingback: Pre-Calculating Semi- and Non-Additive Measures in Power BI – Curated SQL
Thanks, this is great and helped me connect properly to my Azure Data Bricks cluster. But now I got another issue, I connected and could see the tables under Spark – clicking on the table I wanted to connect and saw first few rows of data, but “Load” and “Transform Data” buttons are not enabled. Why is it that? Because my table too big, but it only has a few hundred rows. Where could I pre-filter the data so it would not download the entire table?
hmm, thats indeed weird, that button should not be disabled
but it it definitely has nothing to do with size of your table – PowerBI does not know at this point how big the table is
did you want to connect in Direct Query mode or Import Mode?
Sorry, my bad. I didn’t realize I had to check the box next to the table to enable it; I thought when you click on the table and the rows displayed in the preview window you should already check the box but it does not. After I checked now everything works fine.
Thanks for getting back to me.
Thanks for getting back. I was using Direct Query option. It turned out that I needed to check the box next to the table, even though I selected the table and previewed the rows. Now it worked.
Thanks again!
Is there any way we can put parameter for Http paths or cluster ID. For us after every build in data bricks ansible role regenerates a new cluster ID. So it’s not static,
yes, you can just create a parameter and use it as your server-name or HTTP path
Thanks Gerhard. Can i get the Cluster ID Dynamically from Databricks. Our cluster ID changes after any new build.
Something like this
%sql
SET spark.databricks.clusterUsageTags.clusterId
to get the cluster id to use in POWER BI.
Not that I am aware of.
First of all you need the cluster id before you can execute SQL against it
Second you do not know in which order the SQL statements frim Power BI are executed
I would rather fix the deployment to have a static cluster id where you do not overwrite the cluster during deployment. It is also very bad if you would need to update all Power BI reports after you do a Databricks deployment what your current setup (regardless of the original issue)
Hello Gerhard,
We have created RLS views in Databricks and we are connecting to them from Power BI and Dataflows.
In Power BI we are using the Azure Databricks connector and for authentication we are using Azure Active Directory method
In Dataflows since there is no Azure Databricks connector we are using the Spark connector with Personal Access Token as authenticating method.
Both the methonds work fine when the user has admin rights but the challenge arises when we remove the admin rights of the user.
From Azure Databricks connector it works fine but from the Spark connector we get the following error:
“The user does not have the permission to READ_METADATA on the table ”
Could you please suggest some solution for this issue?
Thanks
RLS is specific to Databricks so I am not really surprised that it does not work with the native Spark connector.
Dont know if there is much you can do about it until the Databricks Connector is finally also available in Dataflows
Thanks Gerhard!!
Hi Gerhard, what would you advice for batch data which is 500k rows per month? Use Databricks or Azure SQL or any other DB for PowerBI?
Basically, can we use databricks for production BI?
500k can usually be imported directly into PowerBI using the native Azure Databricks connector.
guess it depends on how many months you need in your report
you can use incremental refresh to load new data monthly
Pingback: Azure Synapse and Delta Lake | James Serra's Blog
Hi Gerhard
What is the best practice here –
1. To develop the reports by connecting to Databricks using individual PATs.
2. Then, after deploying the report to PowerBI service, change the data source credentials to point to the PAT of the Service Principal so data import is done based on defined schedule.
3. PowerBI report users then need not be having Databricks accounts as the underlying service principal is fetching data for them.
Is my understanding correct?
yes, exactly – if you do not want to use the users PAT, then you can generate a PAT with a service account and use that instead so the refresh runs independent of the user (if the user leaves the company, etc.)
the PAT can be changed manually or via the Power BI REST API
for development purposes the user can connect using their AAD user
Hi Gerhard
If you have tried this, can you please share a sample screenshot? What authentication type should we choose? Oauth2 or Basic or Key?
well, whatever authentication you want to use – up to you and your requirements I would say
OAuth if you want to use your Azure Account and Key if you want to use a Personal Access Token (PAT)
-gerhard
For me have different issue- When i install powerBI desktop on my system i have Azure databrick connector but when install similar version on my RDP server which is windows 2016 data center version, could not find Azure databrick connector. so is there anyway to troubleshoot why not getting azure databrick connector on RDP server in powerBI desktop.
if you install the latest version on both systems they should come with the same connectors
can you check in the version number if they are really the same version?
just open PBI Desktop -> Help -> About