Microsoft Fabric has a lot of different components which usually work very well together. However, even though Power BI is a fundamental part of Fabric, there is not really a tight integration between Data Engineering components and Power BI. In this blog post I will show you an easy and reusable way to query the Power BI REST API via Fabric SQL in a very straight forward way. The extracted data can then be stored in the data lake e.g. to create a history of your dataset refreshes, the state of your workspaces or any other information that is provided by the REST API.
To achieve this, we need to prepare a couple of things first:
- get an access token to work with the Power BI REST API
- expose the access token as a SQL variable
- create a PySpark function to query the Power BI REST API
- expose the PySpark function as a SQL user-defined function
- use SQL to query the Power BI REST API
To get an access token for the Power BI REST API we can use mssparkutils.credentials.getToken and provide the OAuth audience for the Power BI REST API which would be https://analysis.windows.net/powerbi/api
pbi_access_token = mssparkutils.credentials.getToken("https://analysis.windows.net/powerbi/api")
We then need to make this token available in Fabric Spark SQL by storing it in a variable:
spark.sql(f"SET pbi_access_token={pbi_access_token}")
The next part is probably the most complex one. We need to write a Python function that runs a query against the Power BI REST API and returns the results in a standardized way. I will not go into too much detail but simply show the code. It basically queries the REST API via a GET request, checks if the result contains a property value with the results and then returns them as a list of items. Please check e.g. the GET Groups REST API call to better understand the structure of the result. The function further adds a new property to each item to make nesting of API calls easier as you will see in the final example.
import requests
# make sure to support different versions of the API path passed to the function
def get_api_path(path: str) -> str:
base_path = "https://api.powerbi.com/v1.0/myorg/"
base_items = list(filter(lambda x: x, base_path.split("/")))
path_items = list(filter(lambda x: x, path.split("/")))
index = path_items.index(base_items[-1]) if base_items[-1] in path_items else -1
return base_path + "/".join(path_items[index+1:])
# call the api_path with the given token and return the list in the "value" property
def pbi_api(api_path: str, token: str) -> object:
result = requests.get(get_api_path(api_path), headers = {"authorization": "Bearer " + token})
if not result.ok:
return [{"status_code": result.status_code, "error": result.reason}]
json = result.json()
if not "value" in json:
return []
values = json["value"]
for value in values:
if "id" in value:
value["apiPath"] = f"{api_path}/{value['id']}"
else:
value["apiPath"] = f"{api_path}"
return values
Once we have our Python function, we can make it accessible to Spark. In order to do this, we need to define a Spark data type that is returned by our function. To make it work with all different kinds of API calls without knowing all potential properties that might get returned, we use a map type with string keys and string values to cover all variations in the different APIs. As the result is always a list of items, we wrap our map type into an array type.
The following code exposes it to PySpark and also Spark SQL.
import pyspark.sql.functions as F
import pyspark.sql.types as T
# schema of the function output - an array of maps to make it work with all API outputs
schema = T.ArrayType(
T.MapType(T.StringType(), T.StringType())
)
# register the function for PySpark
pbi_api_udf = F.udf(lambda api_path, token: pbi_api(api_path, token), schema)
# register the function for SparkSQL
spark.udf.register("pbi_api_udf", pbi_api_udf)
Now we are finally ready to query the Power BI REST API via Spark SQL. We need to use the magic %%sql to tell the notebook engine, we are running SQL code in this one cell. We then run our function in a simple SELECT statement and provide the API endpoint we want to query and a reference to our token-variable using the variable syntax ${variable-name}.
%%sql
SELECT pbi_api_udf('/groups', '${pbi_access_token}') as workspaces
This will return a table with a single row and a single cell:
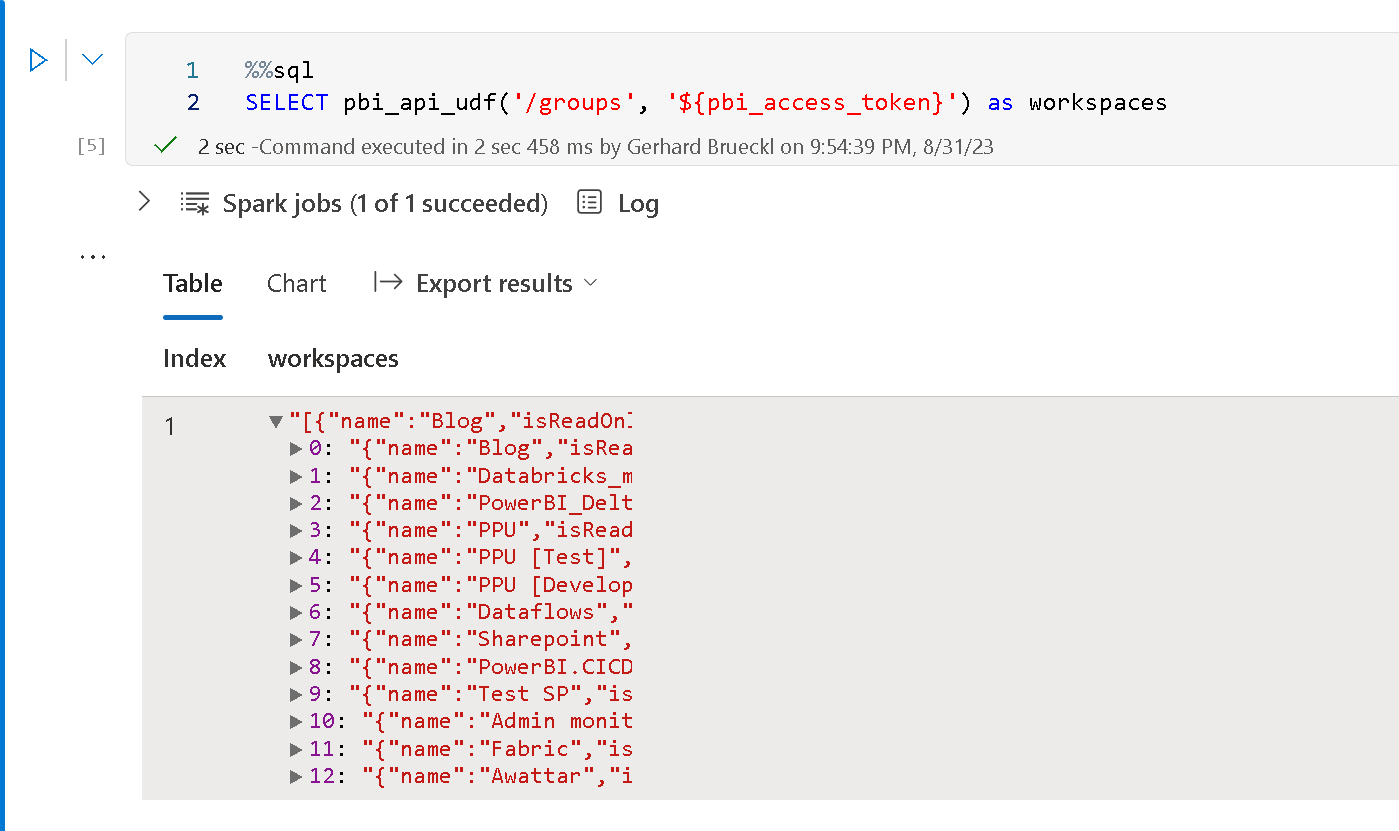
However, that cell contains an array which can be exploded to get our actual list of workspaces and their details:
%%sql
SELECT explode(pbi_api_udf('/groups', '${pbi_access_token}')) as workspace
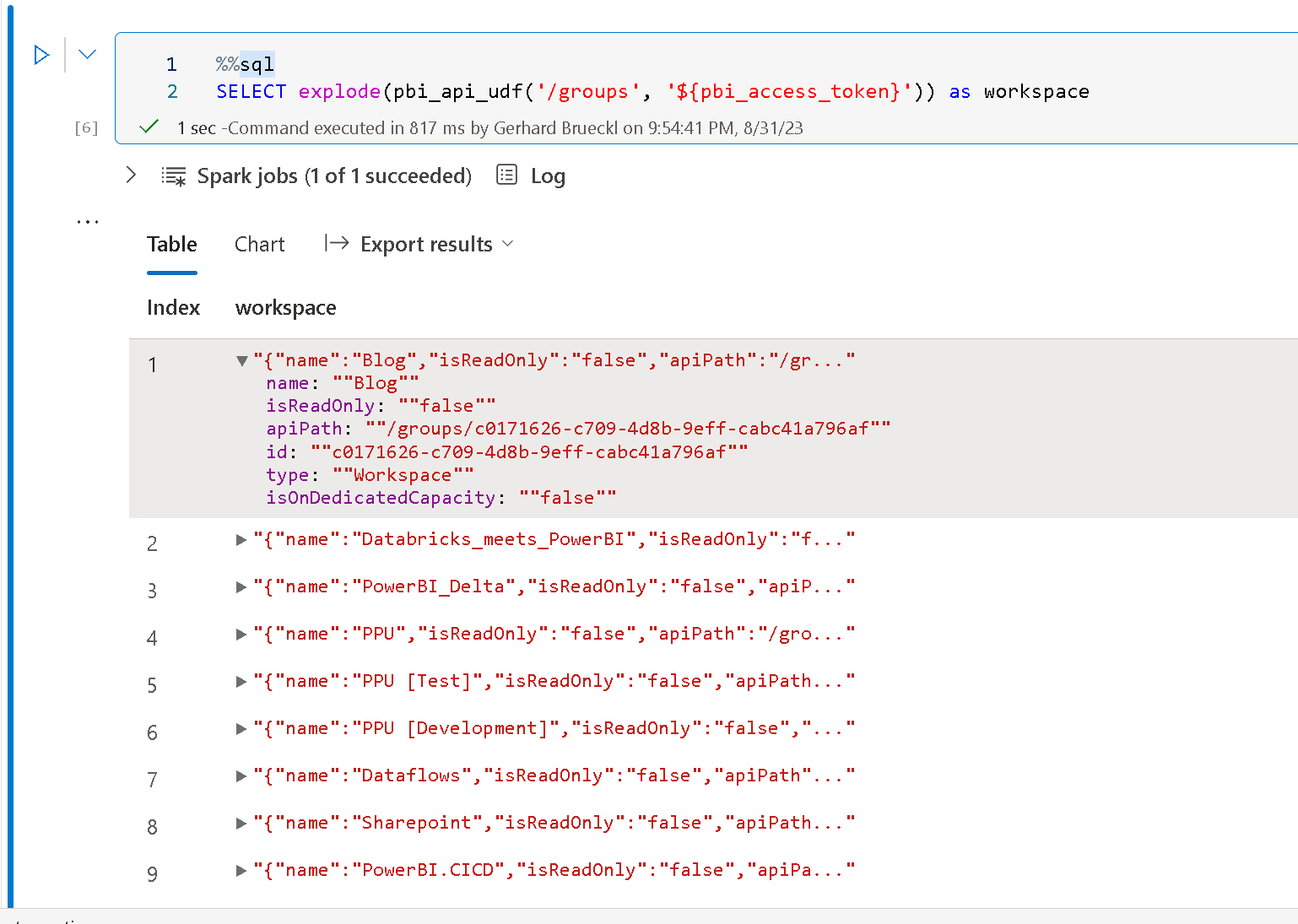
Once you understood those concepts, it is pretty easy to query the Power BI REST API via SQL as this can also be combined with other Spark SQL capabilities like CTEs, e.g. to get a list of all datasets across all workspaces as shown below:
%%sql
WITH cte_workspaces AS (
SELECT explode(pbi_api_udf('/groups', '${pbi_access_token}')) as workspace
)
SELECT workspace.name, workspace.id, pbi_api_udf(concat(workspace.apiPath, '/datasets'), '${pbi_access_token}') as datasets
FROM cte_workspaces
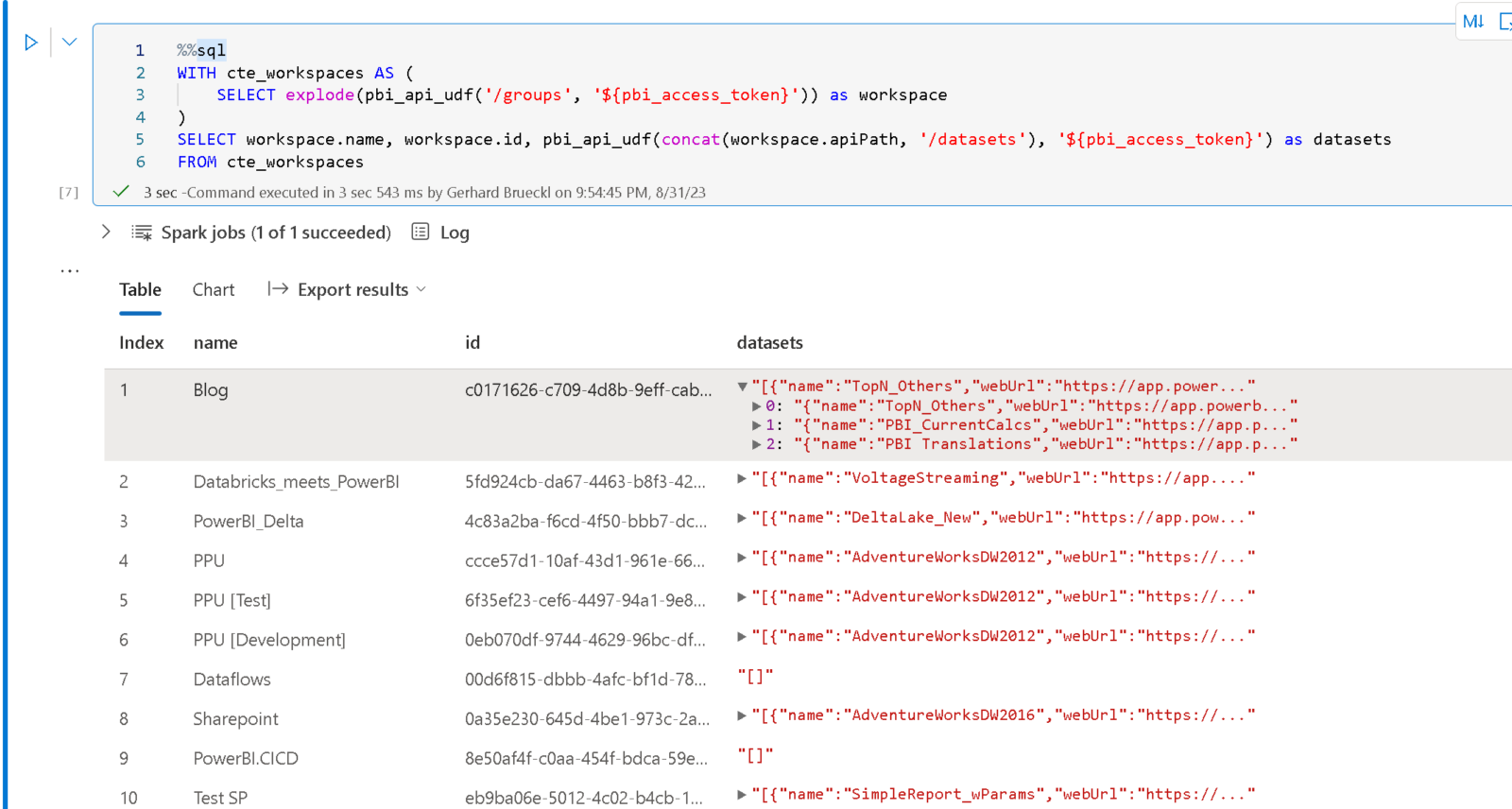
As you can see, to show a given property as a separate column, you can just use the dot-notation to reference it – e.g. workspace.name or workspace.id
There are endless possibilities using this solution, from easy interactive querying to historically persisting the state of your Power BI objects in your data lake!
Obviously, there are still some things that could be improved. It would be much more elegant to have a Table Valued Function instead of the scalar function that returns an array which needs to be exploded afterwards. However, this is not yet possible in Fabric but will hopefully come soon.
This technique can also be applied to any other APIs that expose data. The most challenging part is usually the authentication but Fabric’s mssparkutils.credentials make it pretty easy for us to do this.