PowerBI.CICD repository
In the past I have been working on a lot of different Power BI projects and it has always been (and still is) a pain when it comes to the deployment of changes across multiple tiers(e.g. Dev/Test/Prod). The main problem here being that a file generated in Power BI desktop (</mark>.pbix<mark style="background-color:#ffffff" class="has-inline-color has-black-color">) is basically a binary file and the metadata of the actual data model (BIM) cannot be easily extracted or derived. This causes a lot of problems upstream when you want to automate the deployment using CI/CD pipelines. Here are some common approaches to tackle these issues:
- Use of Power BI deployment pipelines
The most native solution, however quite inflexible when it comes to custom and conditional deployments to multiple stages - Creation a Power BI Template (
.pbit) in addition to your.pbix<mark style="background-color:#ffffff" class="has-inline-color has-black-color">file and check in both
This works because the</mark></mark><mark style="background-color:#ffffff" class="has-inline-color">.pbit</mark><mark style="background-color:#ffffff" class="has-inline-color has-black-color"><mark style="background-color:#ffffff" class="has-inline-color has-black-color">file basically contains the BIM file but its creation is also a manual step - Extraction of the BIM file while PBI desktop is still running (e.g. using Tabular Editor)
With the support of external tools this is quite easy, but is still a manual step and requires a 3rd party tool - Development outside of PBI desktop (e.g. using Tabular Editor)
Probably the best solution but unfortunately not really suited for business users and for the data model only but not for the Power Queries
As you can see, there are indeed some options, but none of them is really ideal, especially not for a regular business user (not talking about IT pros). So I made up my mind and came up with the following list of things that I would want to see for proper CI/CD with Power BI files:
- Users should be able to work with their tool of choice (usually PBI desktop, optional with Tabular Editor or any other 3rd party tool)
- Automatically extracting the metadata whenever the data model changes
- Persisting the metadata (BIM) in git to allow easy tracking of changes
- Using the persisted BIM file for further automation (CD)
Solution
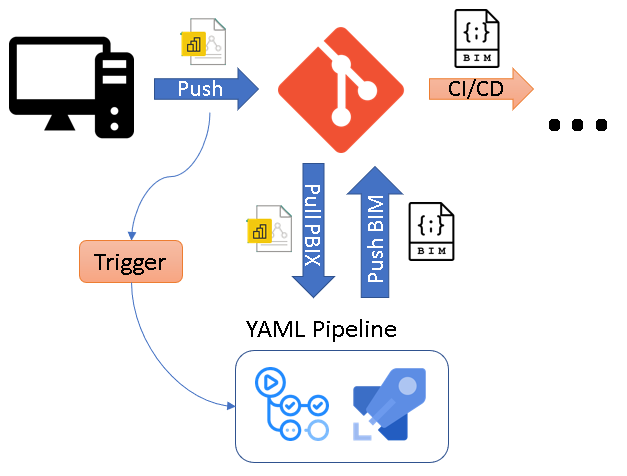
The core idea of the solution is to use CI/CD pipelines that automatically extracts the metadata of a .pbix file as soon as it is pushed to the Git repository. To do this, the .pbix file is automatically uploaded to a Power BI Premium workspace using the Power BI REST API and the free version of Tabular Editor 2 then extracts the BIM file via the XMLA endpoint and push it back to the repository.
I packaged this logic into ready-to-use YAML pipelines for Github Actions and Azure DevOps Pipelines being the two most common choices to use with Power BI. You can just copy the YAML files from the PowerBI.CICD repository to your own repo. Then simply provide the necessary information to authentication against the Power BI service and that’s it. As soon as everything is set up correctly. the pipeline will automatically create a .database.json for every PBIX file that you upload (assuming it contains a data model) and track it in your git repository!
All further details can be found directly in the repository which is also updated frequently!

