As you probably know, we at paiqo have developed our Databricks extension for VSCode over the last years and are constantly adding new features and improving user experience. The most notable features are probably the execution of local notebooks against a Databricks cluster, a nice UI to manage clusters, jobs, secrets, repos, etc. and last but not least also a browser for your workspace and DBFS to sync files locally.
In February 2023 Databricks also published its own official VSCode extension which was definitely long awaited by a lot of customers (blog, extension). It allows you to run a local file on a Databricks cluster and display the results in VSCode again. Alternatively you can also run the code as a workflow. I am sure we can expect much more features in the near future and Databricks investing in local IDE support is already a great step forward!
As you can imagine, I am working very closely with the people at Databricks and we are happy to also announce the next major release of our Databricks VSCode extension 2.0 which now also integrates with the official Databricks extension! To avoid confusion between the two extensions we also renamed ours to Databricks Power Tools so from now on you will see two Databricks icons on the very left bar in VSCode.
By introducing a new connection manager you can now leverage the configuration settings you already have in the Databricks extension and use them in the Databricks Power Tools seamlessly. All you need to do is to change the VSCode configuration to use the new Databricks Extension connection manager as shown below.
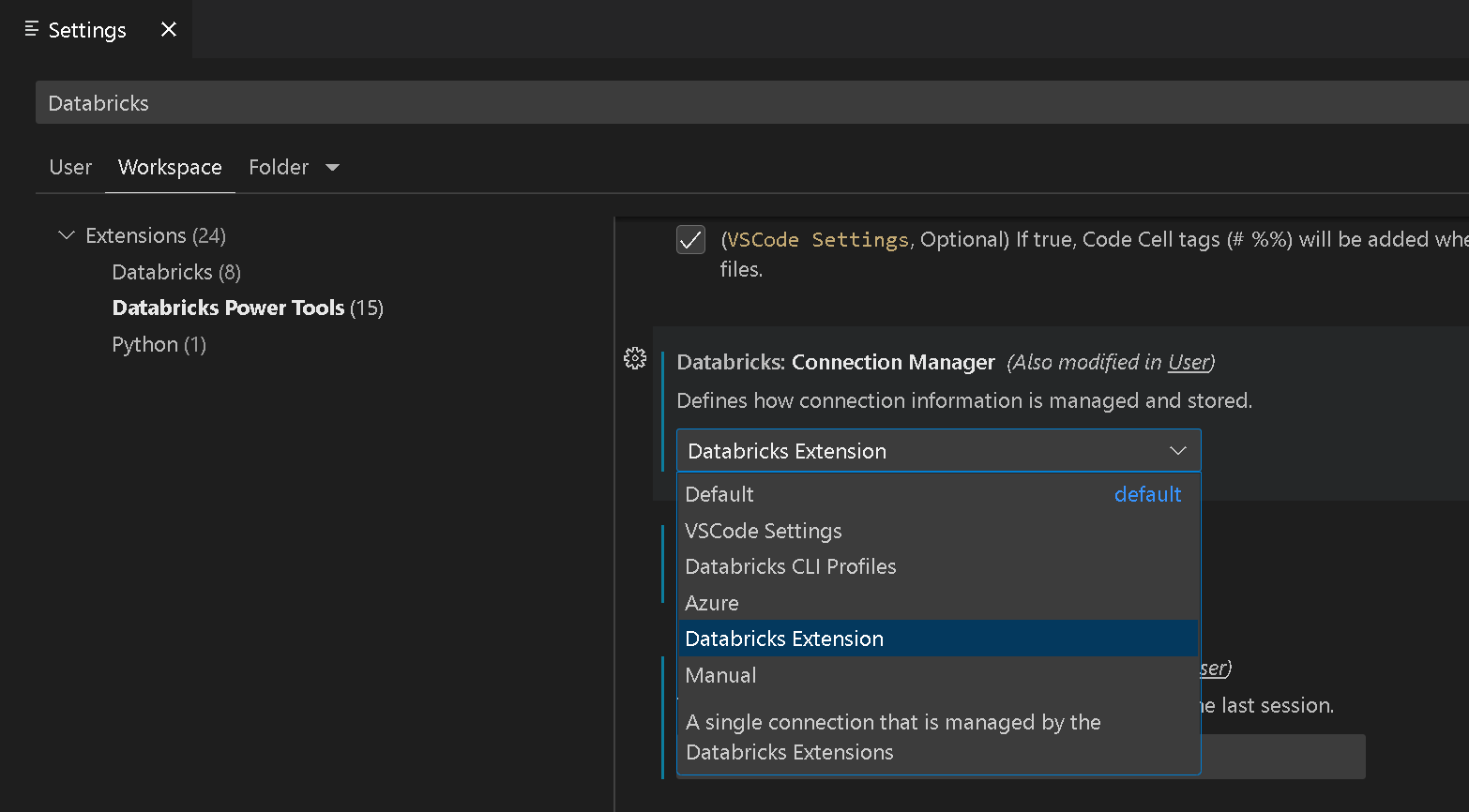
This is also the new default so if you have both extensions installed, the Databricks Power Tools will automatically pick up the configuration settings from the Databricks extension to establish a connection to your Databricks workspace.
If we detect that the Databricks extension is installed already, we also automatically create a new Notebook Kernel for you that allows you to run notebooks against the cluster that you configured in the Databricks extension. To change the cluster where the code runs, you can use the Cluster Manager from the Databricks Power Tools.
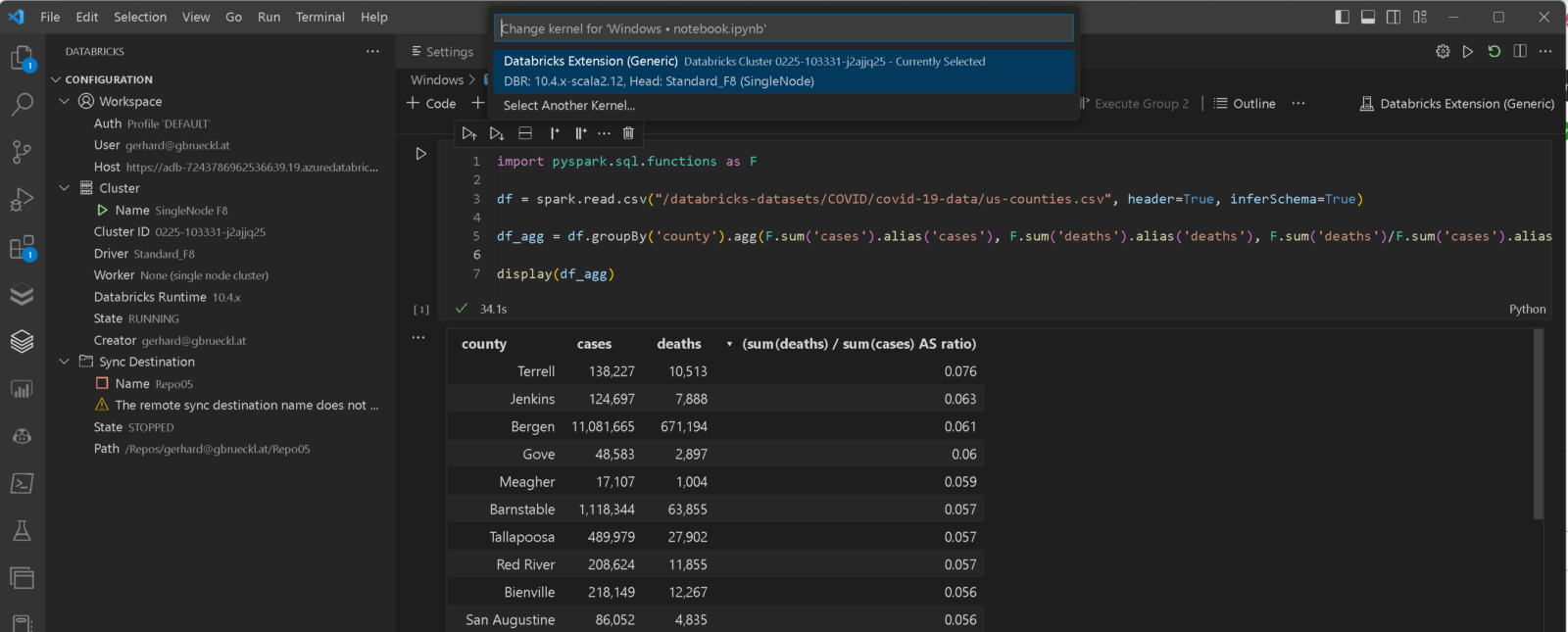
Besides that new integration, there are also a lot of other new features that made it into this major release:
- File system integrations: you can now mount your Databricks workspace or DBFS directly into your VSCode workspace. This also allows you to easily drag & drop items between your local filesystem, Databricks workspace (notebooks) and DBFS!
- A new Azure Connection Manager to automatically load the Databricks Workspaces that you have access to
- Support for Widgets in Notebooks similar to Databricks using
<strong>dbutils.widgets</strong>library - Added support for
<strong>_sql_dfvariable in notebooks when mixing Python and SQL cells - Added support for
<strong>%run</strong>and<strong>dbutils.notebook.run()</strong> - Preparations to make the whole extension also run via vscode.dev but there also need to be some changes made on the Databricks side for this to finally work
- A lot of bug fixes and minor other features
All these improvements together allow you to run most of the code that you currently have in Databricks also from VSCode without any changes! Also the sync between your local files and the Databricks workspace is super easy. You can almost start a new Databricks project without ever opening the Databricks web UI!
Here is a little demo to demonstrate what the Databricks Power Tools can do for you!
We finally got your attention? Great!
Make sure to download the new Databricks Power Tools and try them on your own!
Any feedback is very welcome and if you are as passionate about it as we are you might also want to contribute to the project!
Is it possible to execute standard python files (.py) against a Databricks cluster in Databricks Power Tools for VSCode or will this feature be added in near future?
not directly, as we heavily rely on the VSCode notebook interface to run the queries
However, you can do the following settings to also open regular `.py` files as notebooks with a single cell which can then easily be executed
“`
“settings”: {
“workbench.editorAssociations”:{
“*.py”: “databricks-notebook”,
“*.scala”: “databricks-notebook”,
“*.sql”: “databricks-notebook”,
“*.r”: “databricks-notebook”
}
}
“`
alternatively please also have a look at the official Databricks extension https://marketplace.visualstudio.com/items?itemName=databricks.databricks which supports your scenario better I think
Hello,
I currently work on a streaming project in scala.
I would like to be able to render (see the cells and be able to execute each cell) and run my scala notebook in vscode.
I tried the databricks extension and the databricks power tools extension but was not successful with either of them.
Do you have an idea how I could do this ?
Thank you, have a great day,
Thomas
this is currently not supported by our Databricks Power Tools as it is also not supported by the underlying APIs that we use
not sure about the Databricks Extension itself, but streaming and live-updates are quite complex from an UI point of view and I do not think this will work in VSCode (regardless of the extension)
sorry
Hi,
Is there a way to export the results into a CSV or other format, similar to the native Databricks Notebook experience?
using the […] next to the output cell you can copy the output – however, it will be in JSON I think
we did not implement anything specific to export the results
feel free to open a ticket in the GIT repository so we can investigate if thats feasible
Love the extension. Biggest drawback for me is that I can’t get VS Code to display intermediate results as a cell is running – everything prints only once the cell is finished. Is there any workaround to see print statements while a cell is running?
hmm, good question
from what I can tell the VSCode and Databricks APIs work synchronous. We take the whole code of the cell and send it to the DAtabricks API. Once the code finished, the Databricks API returns the results and we can display them in VSCode
the only workaround would be to split the code into multiple cells
Is possible to sync automatically the notebooks between vscode and DB?
I think this could help to everyone
I guess what you are looking for is our File System Integration
It mounts your Databricks Workspace directly into your VSCode explorer and catches the latest version from Databricks when you open it and saves it back to Databricks when you save it in VSCode
I’ve found that I can’t get matplotlib figures to display when I’m running on a cluster using the 13.3 LTS runtime; the cell output shows up as text (e.g. ). But figures work fine for 12.2.
thanks, there is an open ticket for this in the repo already:
https://github.com/paiqo/Databricks-VSCode/issues/179
unfortunately there is not much we can do about it
Very much interested in using this package.
Unfortunately when trying to install I get the following:
“Error running command databricks.Workspace.download: cannot read properties of undefined (reading ‘Path’). This is likely casued by the extension that contributes to databricks.Workspace.download.
My (official) databricks extension works like a charm.
thanks for the feedback – for bugs please open a ticket here:
https://github.com/paiqo/Databricks-VSCode/issues
Thanks for sharing these invaluable tool Databricks! Grateful for the insights!
This is very great tool. I really need this tool for the Databricks notebook development. However. I get an issue on this tool. The Databricks Power tools cannot fetch any information from the workspace and the notebook cell by cells cannot be executed with the cluster using Databricks Power tools. But I conform the Databricks extension already connected to the workspace cluster and execute the notebook in local.
thanks for the feedback – for bugs please open a ticket here:
https://github.com/paiqo/Databricks-VSCode/issues
please also include your configuration (e.g. Connection Manager, Live or Offline-Mode, etc.)
Is there a way to have the Databricks kernel available also in the Interactive window in VsCode? Many people including myself like to use regular .py files + Interactive window instead of Notebook files.
please create an issue in the Github repo https://github.com/paiqo/Databricks-VSCode/issues
I am happy to follow up there
quick answer upfront: I did some initial tests some time ago and faced issues with not all capabilities for interactive windows were available for custom notebook kernels.