I also contributed the connector described in this post to the official delta.io Connectors page and repo (link). You will find the most recent updates in my personal repo which are then merged to the official repo once it has been tested thoroughly!
Working with analytical data platforms and big data on a daily basis, I was quite happy when Microsoft finally announced a connector for Parquet files back in November 2020. The Parquet file format is developed by the Apache foundation as an open-source project and has become a fundamental part of most data lake systems nowadays.
“Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.”
However, Parquet is just a file format and does not really support you when it comes to data management. Common data manipulation operations (DML) like updates and deletes still need to be handled manually by the data pipeline. This was one of the reasons why Delta Lake (delta.io) was developed besides a lot of other features like ACID transactions, proper meta data handling and a lot more. If you are interested in the details, please follow the link above.
So what is a Delta Lake table and how is it related to Parquet? Basically a Delta Lake table is a folder in your Data Lake (or wherever you store your data) and consists of two parts:
- Delta log files (in the sub-folder _delta_log)
- Data files (Parquet files in the root folder or sub-folders if partitioning is used)
The Delta log persists all transactions that modified the data or meta data in the table. For example, if you execute an INSERT statement, a new transaction is created in the Delta log and a new file is added to the data files which is referenced by the Delta log. If a DELETE statement is executed, a particular set of data files is (logically) removed from the Delta log but the data file still resides in the folder for a certain time. So we cannot just simply read all Parquet files in the root folder but need to process the Delta log first so we know which Parquet files are valid for the latest state of the table.
These logs are usually stored as JSON files (actually JSONL files to be more precise). After 10 transactions, a so-called checkpoint-file is created which is in Parquet format and stores all transactions up to that point in time. The relevant logs for the final table are then the combination of the last checkpoint-file and the JSON files that were created afterwards. If you are interested in all the details on how the Delta Log works, here is the full Delta Log protocol specification.
From those logs we get the information which Parquet files in the main folder must be processed to obtain the final table. The content of those Parquet files can then simply be combined and loaded into PowerBI.
I encapsulated all this logic into a custom Power Query function which takes the folder listing of the Delta table folder as input and returns the content of the Delta table. The folder listing can either come from an Azure Data Lake Store, a local folder, or an Azure Blob Storage. The mandatory fields/columns are [Content], [Name] and [Folder Path]. There is also an optional parameter which allows you the specify further options for reading the Delta table like the Version if you want to use time-travel. However, this is still experimental and if you want to get the latest state of the table, you can simply omit it.
The most current M-code for the function can be found in my Github repository for PowerBI: fn_ReadDeltaTable.pq and will also be constantly updated there if I find any improvement.
The repository also contains an PowerBI desktop file (.pbix) where you can see the single steps that make up for the final function.
Once you have added the function to your PowerBI / Power Query environment you can call it like this:
= fn_ReadDeltaTable(
AzureStorage.DataLake(
"https://myadls.dfs.core.windows.net/public/data/MyDeltaTable.delta",
[HierarchicalNavigation = false]),
[Version = 12])
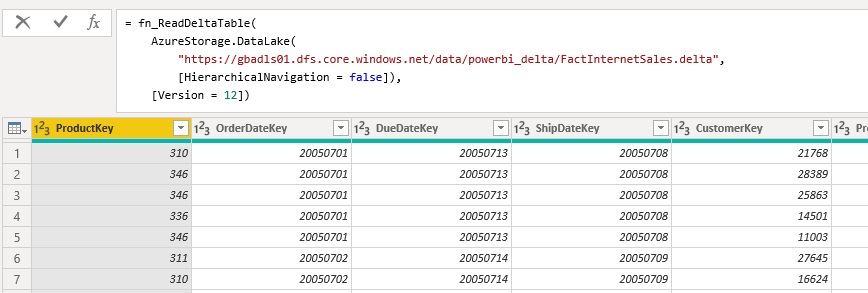
I would further recommend to nest your queries and separate the access to the storage (e.g. Azure Data Lake Store) and the reading of the table (execution of the function). If you are reading for an ADLS, it is mandatory to also specify [HierarchicalNavigation = false] ! If you are reading from a blob storage, the standard folder listing is slightly different and needs to be changed.
Right now the connector/function is still experimental and performance is not yet optimal. But I hope to get this fixed in the near future to have a native way to read and finally visualize Delta lake tables in PowerBI.
After some thorough testing the connector/function finally reached a state where it can be used without any major blocking issues, however there are still some known limitations:
- Partitioned tables
currently columns used for partitioning will always have the value NULLFIXED!values for partitioning columns are not stored as part of the parquet file but need to be derived from the folder pathFIXED!
- Performance
is currently not great but this is mainly related to the Parquet connector as it seems- very much depends on your data – please test on your own!
- Time Travel
currently only supports “VERSION AS OF”need to add “TIMESTAMP AS OF”
- Predicate Pushdown / Partition Elimination
currently not supported – it always reads the whole tableFIXED!
Any feedback is welcome!
Special thanks also goes to Imke Feldmann (@TheBIccountant, blog) and Chris Webb (@cwebb_bi, blog) who helped me writing and tuning the PQ function!
Downloads: fn_ReadDeltaTable.pq (M-code)
This is exactly what I needed, great work, thanks!
Really great work and nicely explained!
Thanks for sharing. This is really super nice.
I’ll make sure to add a comment on top off the function pointing towards your repository.
This is exactly what I needed however it looks like this makes it a dynamic data source so refresh isn’t supported in Power BI Service. Any idea if there’s a way around that?
Whats your data source? This is actually related to the datasource and not so much to the Delta-function.
I will also run some more tests on this to check whats working and whats not
My data is in a delta table in ADLS Gen2 storage. Any help you can offer would be much appreciated!
I just had a look at the code and it seems there was some regression when partition filters where introduced which made the whole function generate a dynamic datasource
if you do not want/need to filter for specific partitions only or do not need to leverage partition filtering, you can use this older version of the code:
https://github.com/gbrueckl/PowerBI/blob/e60e14c0c5815e688d7ef572eb0648ec0bca0df5/PowerQuery/DeltaLake/fn_ReadDeltaTable.pq
I could also fix the latest could so it still supports partition elimination, etc. in combination with online refresh
https://github.com/gbrueckl/connectors/blob/master/powerbi/fn_ReadDeltaTable.pq
Nice work, congratulations for your advance Gerhard.
Hey Gerhard
Can you give a full example for an ADLS 2 in the readme? I was not able to perform the connection to a delta folder. I got an authentication error
Hi Kevin,
if you get an authentication error then this is not related to the Delta Table function.
The function does not deal with authentication but expects a file-listing of the delta-table for which to obtain it, you need to have access to the source
If you cannot access your ADLS Gen2 you also cannot read a delta table from there – I think this should be clear – no?
regards,
-gerhard
Pingback: The Ubiquity of Delta Standalone: Java, Scala, Hive, Presto, Trino, Power BI, and More! – Slacker News
Pingback: The Ubiquity of the Delta Standalone Venture for Delta Lake – DatasClick
Pingback: The Ubiquity of Delta Standalone: Java, Scala, Hive, Presto, Trino, Power BI, and More!
Hello Gerhard,
Does this method work to read data in ADL v2, or is only supported for ADL V1?
sure, you can connect to ADLS Gen2 like this:
= AzureStorage.DataLake("https://gbadls01.dfs.core.windows.net/public/powerbi_delta/DimProduct.delta", [HierarchicalNavigation = false])and then feed this table into the fn_ReadDeltaTable function
The example in the blog post also shows you how to use it with ADLS Gen2
Thank you for this very useful code. Would you leverage views in Synapse Serverless Pools, if you had the opportunity, over directly ingesting into Power BI?
For Direct Query mode (DQ), your only option is Synapse Serverless Pools (or Databricks/Spark)
Also, if you want to do joins or need complex transformations across tables, I would suggest a dedicated Big Data Processing engine like Synapse or Databricks, especially when the involved tables are big
for small tables and models where you do not need real-time or DQ, using the Delta connector is definitely the cheaper and less complex option as it does not involve anything except PBI itself
-gerhard
Hi,
Interesting! what do you mean by “small tables and models” of course there is no hard threshold but approximately what are the recommended magnitudes?
I would say as long as you stay <10M rows you should be fine.
In the end it is just another way of loading data - the more data you load, the long it will take.
Once the data is loaded it does not make a difference anymore where it originally came from
Unfortunately I get a weird error when reading the delta table from the ADLS Gen 2. Error Message:
Could not load file or assembly ‘ParquetSharp, Version=0.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35’ or one of its dependencies. The system cannot find the file specified.
Any suggestions on this one?
thanks!
very much looks like an error related to your Power BI installation – but definitely not related to the connector
That error is 100% related to your installation. It looks like something funky happened with the November 2022 update, my coworker had the same error but upgrading to the December 2022 update fixed the problem. https://community.powerbi.com/t5/Issues/Parquet-connector-error-after-November22-Update/idi-p/2944085
Hello Gerhard,
Thanks for this amazing work!
Could you please help, how can we pass the parameter values in this function so that we can get data only for that parameter from the ADLS gen2 file.
Example – I wanted to apply where clause on date field in the function so that, I will pull data only for that date range and not all the data from paruqet file places in ADLS Gen2.
It will be very helpful if you help in this scenario as early as possible.
Thanks
I think what you are looking for is already described in the docs. You need to use the PartitionFilterFunction parameter:
https://github.com/delta-io/connectors/tree/master/powerbi#reading-from-azure-data-lake-store-gen2
however, this will only work if your table is already partitioned by the column you want to filter on – otherwise you file pruning will not work
Good day,
I’m taking my first steps in connecting Power BI to DeltaLake.
I have Azure ADLSgen2 storage and using the method from the examples:
let
Source = AzureStorage.DataLake(“https://MyStorageAccount.dfs.core.windows.net/path to DeltaTableFolder/”),
DeltaTable = fn_ReadDeltaTable(Source,[Version=1])
in
DeltaTable
Played with options Version, UseFileBuffeer, HirarchicalNavigation, and IterateFolderContent but didn’t get much progress.
I experienced the issue that some tables I cannot read and have to specify the version number. Also based on the log file it has higher versions but again I’m not able to define the most recent version.
Some tables show me errors something like ( “Table_Name already exists..” or “Point to specific object instance” ?)
Would be great if you could advise me on how to debug my issues?
Thank you in advance!
so if you do not specify an explicit version in the options (2nd parameter), the latest version of the table will be read – so you can omit it unless you want to read a specific historic version
also, the other options are only for specific scenarios
this code should just work fine
let Source = AzureStorage.DataLake(“https://MyStorageAccount.dfs.core.windows.net/path to DeltaTableFolder/”), DeltaTable = fn_ReadDeltaTable(Source) in DeltaTable“Table_Name already exists” is probably a Power Query error and you just need to rename your query
“Point to specific object instance” – I have never seen this error before, sorry
Thank you for your comment.
If I do exactly like this:
”let
Source = AzureStorage.DataLake(“https://MyStorageAccount.dfs.core.windows.net/path to DeltaTableFolder/”),
DeltaTable = fn_ReadDeltaTable(Source)
in
DeltaTable”
I’m getting : “Object reference not set to an instance of an object”
but when
”let
Source = AzureStorage.DataLake(“https://MyStorageAccount.dfs.core.windows.net/path to DeltaTableFolder/”),
DeltaTable = fn_ReadDeltaTable(Source, [Version=1])
in
DeltaTable”
Its ok
If I see via Azure Storage Explorer its looks like there are multiple versions with partitioning
I see Folders:
DeltaTableFolder/
DeltaTableFolder/_delta_log
DeltaTableFolder/year=2023
inside /DeltaTableFolder/_delta_log I see 000xxx00.json up to 00xxx39.json.
Based on it I make a decision that I do have the version up to 39.
My goal is to get the most recent version of the table but Im getting errors if Om not using the second parameter. As well I cannot get higher than 18 [Version=18]
Would be great if you could share with me your thought of this issue?
Your example unfortunately not works for me (not work for some tables). When I’m using a second parameter [Version=1 and up to Version=19] and only from the specific limited range ( my json’s have names from 000xxx000.json to 00xx00039.json) then it read the table.
The table has partitions and columns to filter but I was not able to get successful results.
Maybe it is because too many versions?
Any ideas on how better to debug?
does the table work if you read it with any other tool (e.g. Spark, Synapse, Databricks, etc.) ?
if versions up to 19 are working, there might be an issue with your checkpoint which is usually created after 10 transactions/versions
so every 10 versions you should also see a .parquet file in the _delta_log folder. can you check if 00000020.parquet is there?
PowerBI also recently introduced its own Delta lake function called “DelataLake.Table” – you might also want to try this
regards,
-gerhard
Hi Gerhard,
Unfortunately, I’m approaching the problem from the consumer side ( PowerBI ). I don’t have any control over the delta lake. I see only the folders and files.
Yes, I see the files you described. (every 10x .checkpoint.parquet, 000xxxNN.json and _last_checkpoint)
I analyzed all my success tables reading from the partitioned DeltaLake Tables (no issue) and would able to come to the conclusion that the function reads OK once the folder does not contain any checkpoint file. If checkpoint exists -> error.
_last_checkpoint file contains the next record:
{“version”:20,”size”:48}
Also, thank you for pointing me on DeltaLake.Table(). Started to play around but did not get yet good results.
Thanks,
Slava
well, if your _last_checkpoint file points to a version 20 and there is no 0000020.checkpoint.parquet you will get an error but then basically your delta table is corrupt I would say
This file exists but this particular version [Versio=20] I cannot read ( Error msg: Object reference not set to an instance of an object)
Let me add details for a better picture:
Folder has:
000xx00.json
…
0000xx10.checkpoint.parquet
000..10.json
….
0000xxx20.json
0000xxx20.checkpoint.parquet
000xxx21.json (latest)
no missing files
_last_checkpoint (shows: {“version”:20,”size”:48})
1. When I’, using function without any second parameters or [Version=20..21]
( Error msg: Object reference not set to an instance of an object)
2. When I, use [Version=1..11] it reads the table OK
3. When I, using [Version=12..19]
(Error msg: The field “file_name” exists in the records. Details Name = file_name)
When I’m opening:
000xxxxxx.json
it has “commitInfo” section which contains the current “version” of a file as well as the previous “readVersion” as well as a few other sections. Versioning across all 21 json file looks to me consistent.
can you share the zipped logs via the contact form https://blog.gbrueckl.at/about/ ?
there should not be any confidential information in there
I have a guess that it might be related to some metadata-only transactions – e.g. renaming a column or so
It is in a place. Sorry, I was confused above.
I have few errors here:
1. (Error msg: The field “file_name” exists in the records. Details Name = file_name) It looks like this is due to available column in delta table with the name “file_name”.
2. ( Error msg: Object reference not set to an instance of an object) The nature of this one is not clear
Hi, we are using this connector with great success. One item to point out that initially held us up was incorrect partitioning of our data lake to begin with. The connector would fail if we did not follow the published best practice of 1gig or greater per partition. On small partitions the connector would fail but we would not see any issue in interacting with the same data lake via databricks.
Question for you Gerhard, is it possible to do incremental refresh with this connector within powerbi? I see the partition filter function but do not believe that is providing the same functionality. Is it some combination of partition filter function and version to use within powerbi to get the incremental refresh? or something else? or not available at all?
Thank you very much
technically incremental refresh should also work with the connector the very same way it does with any other connector/data source.
if your Delta table is partitionted by date, you would need to specify that filter within the PartitionFilterFunction parameter to make the query more efficient
regarding partitions – I have not yet had an issue with too many partitions and I tested it with 1000 partitions. how many did you have in your initial setup that caused issues?
-gerhard
Hi, This is great and working good for me. However, is there any documentation to understand the fn_ReadDeltaTable.pq function? I don’t want everything to be added in my custom connection and wanted to get rid of any additional functions defined and thus it would be very helpful
documentation exists in the repository: https://github.com/delta-io/delta/blob/master/connectors/powerbi/README.md
let me know if you need anything else
Pingback: Read data from Delta Lake tables with the DeltaLake.Table M function
I am not sure if this is still active blog. I am trying to connect to a delta table from a MS Fabric Lakehouse. My delta table is pretty big (around 6 TB of data (900 Billion rows)), and it is partitioned by day and hour. One hour normallly have around 40 million rows on average. What i am looking for is a direct Query solution that would allow the user to change the day and hour from the report itself, then using dynamic M Query the data would be refreshed accordingly. I am not sure how can i enable direct query? any suggestions. Thanks
so that table is already quite big and its probably not feasible to load it into Import Mode.
if that table is already in a Fabric Lakehouse, you could easily query it via the SQL Endpoint that comes with the lakehouse. If you filter on Day and hour, partition elimination/pruning should kick in and the query should be reasonably fast
for DQ with parameters there are some other blogposts out there:
https://pbi-guy.com/2023/07/14/use-dynamic-m-parameters-in-directquery-mode-and-paginated-reports/
the solution provided here in this blog post will not work for your scenario