Microsoft Fabric has a lot of different components which usually work very well together. However, even though Power BI is a fundamental part of Fabric, there is not really a tight integration between Data Engineering components and Power BI. In this blog post I will show you an easy and reusable way to query the Power BI REST API via Fabric SQL in a very straight forward way. The extracted data can then be stored in the data lake e.g. to create a history of your dataset refreshes, the state of your workspaces or any other information that is provided by the REST API.
To achieve this, we need to prepare a couple of things first:
- get an access token to work with the Power BI REST API
- expose the access token as a SQL variable
- create a PySpark function to query the Power BI REST API
- expose the PySpark function as a SQL user-defined function
- use SQL to query the Power BI REST API
To get an access token for the Power BI REST API we can use mssparkutils.credentials.getToken and provide the OAuth audience for the Power BI REST API which would be https://analysis.windows.net/powerbi/api
pbi_access_token = mssparkutils.credentials.getToken("https://analysis.windows.net/powerbi/api")
We then need to make this token available in Fabric Spark SQL by storing it in a variable:
spark.sql(f"SET pbi_access_token={pbi_access_token}")
The next part is probably the most complex one. We need to write a Python function that runs a query against the Power BI REST API and returns the results in a standardized way. I will not go into too much detail but simply show the code. It basically queries the REST API via a GET request, checks if the result contains a property value with the results and then returns them as a list of items. Please check e.g. the GET Groups REST API call to better understand the structure of the result. The function further adds a new property to each item to make nesting of API calls easier as you will see in the final example.
import requests
# make sure to support different versions of the API path passed to the function
def get_api_path(path: str) -> str:
base_path = "https://api.powerbi.com/v1.0/myorg/"
base_items = list(filter(lambda x: x, base_path.split("/")))
path_items = list(filter(lambda x: x, path.split("/")))
index = path_items.index(base_items[-1]) if base_items[-1] in path_items else -1
return base_path + "/".join(path_items[index+1:])
# call the api_path with the given token and return the list in the "value" property
def pbi_api(api_path: str, token: str) -> object:
result = requests.get(get_api_path(api_path), headers = {"authorization": "Bearer " + token})
if not result.ok:
return [{"status_code": result.status_code, "error": result.reason}]
json = result.json()
if not "value" in json:
return []
values = json["value"]
for value in values:
if "id" in value:
value["apiPath"] = f"{api_path}/{value['id']}"
else:
value["apiPath"] = f"{api_path}"
return values
Once we have our Python function, we can make it accessible to Spark. In order to do this, we need to define a Spark data type that is returned by our function. To make it work with all different kinds of API calls without knowing all potential properties that might get returned, we use a map type with string keys and string values to cover all variations in the different APIs. As the result is always a list of items, we wrap our map type into an array type.
The following code exposes it to PySpark and also Spark SQL.
import pyspark.sql.functions as F
import pyspark.sql.types as T
# schema of the function output - an array of maps to make it work with all API outputs
schema = T.ArrayType(
T.MapType(T.StringType(), T.StringType())
)
# register the function for PySpark
pbi_api_udf = F.udf(lambda api_path, token: pbi_api(api_path, token), schema)
# register the function for SparkSQL
spark.udf.register("pbi_api_udf", pbi_api_udf)
Now we are finally ready to query the Power BI REST API via Spark SQL. We need to use the magic %%sql to tell the notebook engine, we are running SQL code in this one cell. We then run our function in a simple SELECT statement and provide the API endpoint we want to query and a reference to our token-variable using the variable syntax ${variable-name}.
%%sql
SELECT pbi_api_udf('/groups', '${pbi_access_token}') as workspaces
This will return a table with a single row and a single cell:
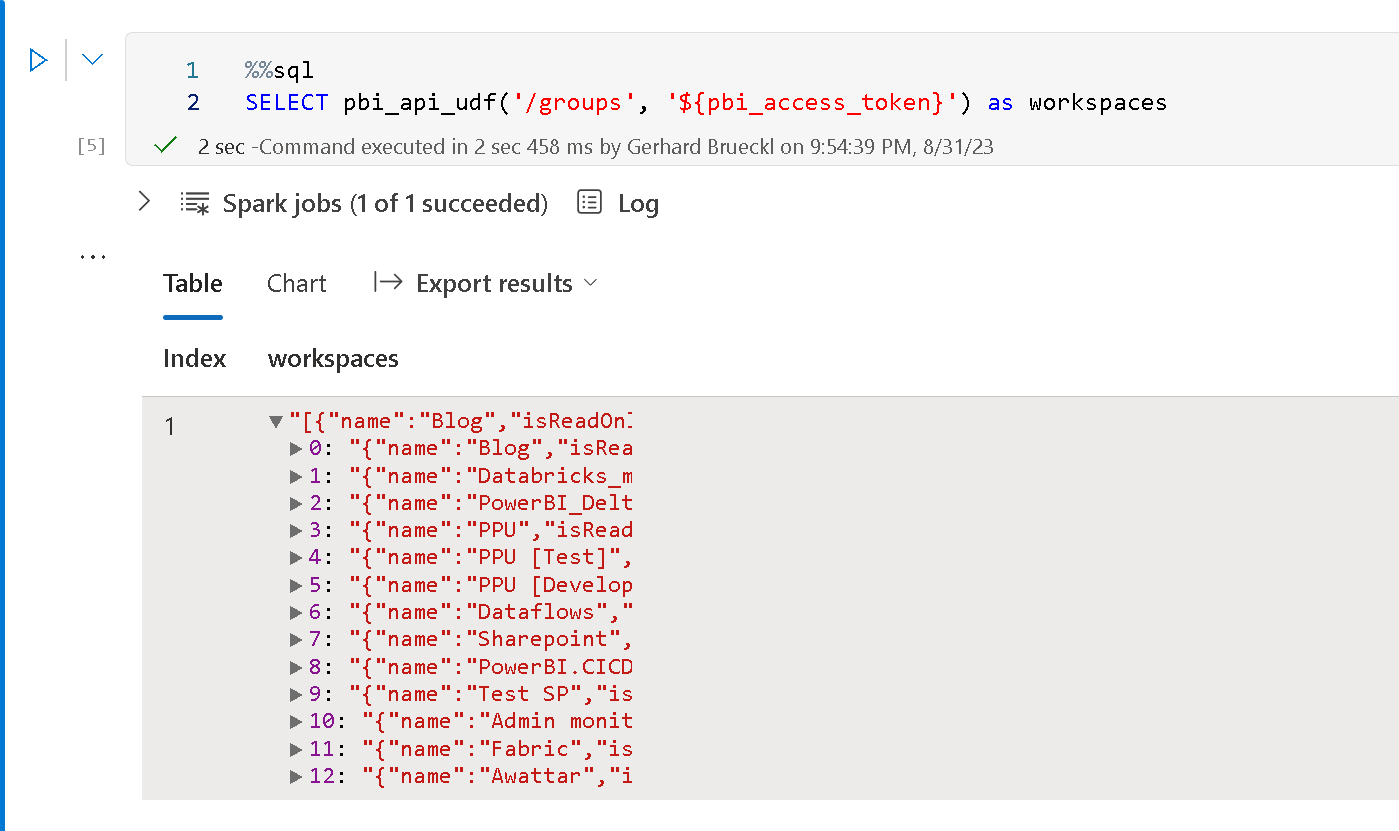
However, that cell contains an array which can be exploded to get our actual list of workspaces and their details:
%%sql
SELECT explode(pbi_api_udf('/groups', '${pbi_access_token}')) as workspace
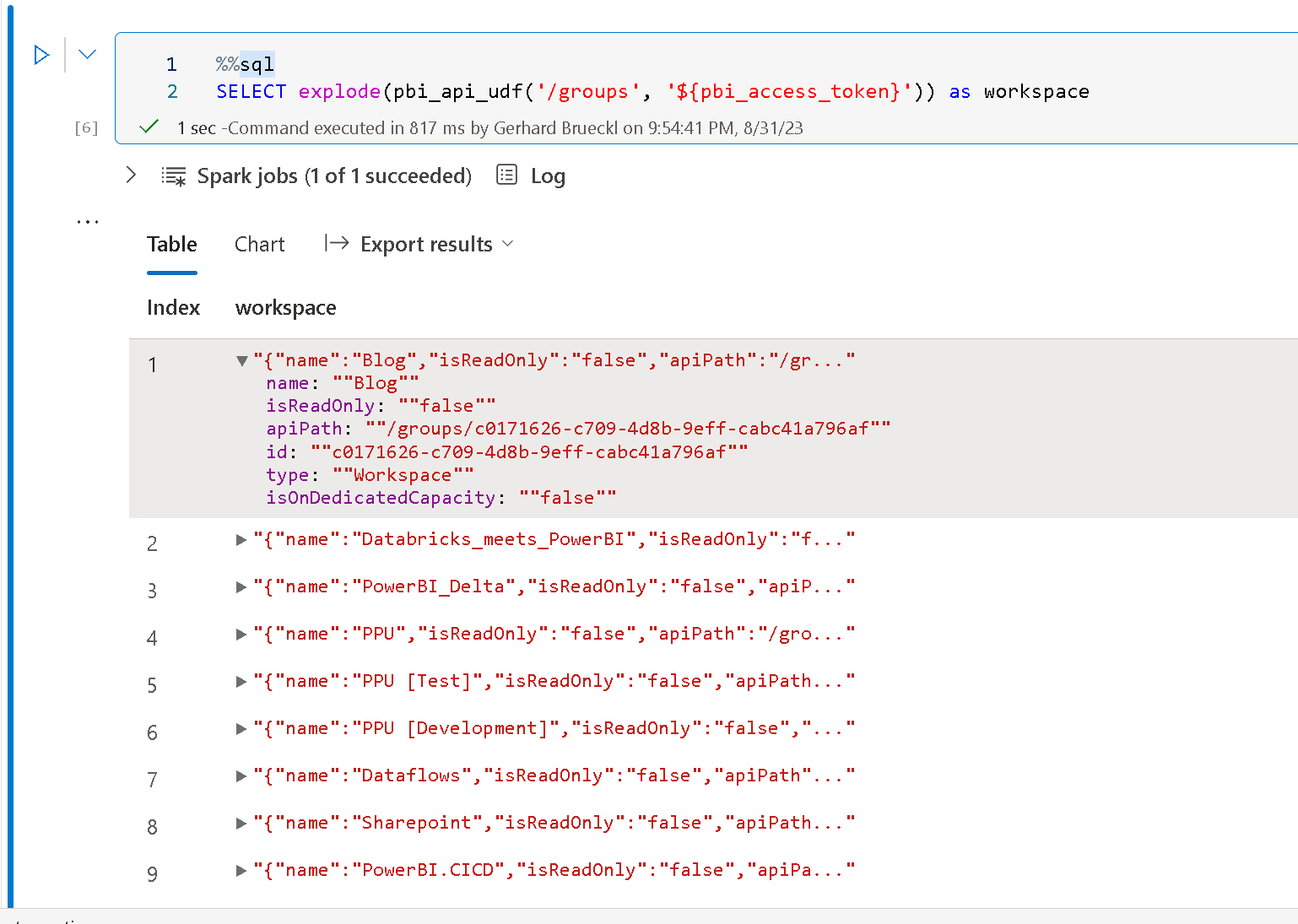
Once you understood those concepts, it is pretty easy to query the Power BI REST API via SQL as this can also be combined with other Spark SQL capabilities like CTEs, e.g. to get a list of all datasets across all workspaces as shown below:
%%sql
WITH cte_workspaces AS (
SELECT explode(pbi_api_udf('/groups', '${pbi_access_token}')) as workspace
)
SELECT workspace.name, workspace.id, pbi_api_udf(concat(workspace.apiPath, '/datasets'), '${pbi_access_token}') as datasets
FROM cte_workspaces
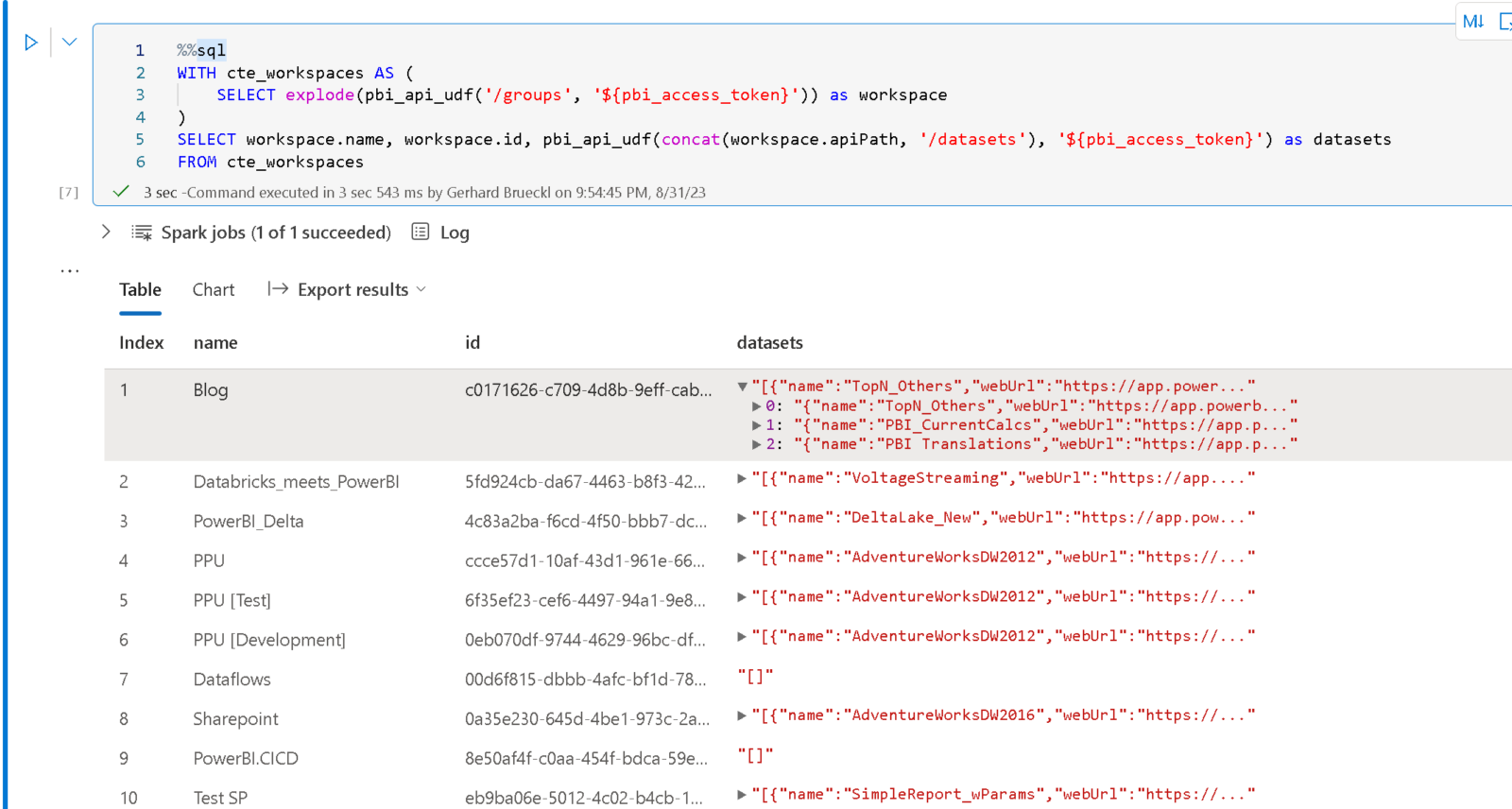
As you can see, to show a given property as a separate column, you can just use the dot-notation to reference it – e.g. workspace.name or workspace.id
There are endless possibilities using this solution, from easy interactive querying to historically persisting the state of your Power BI objects in your data lake!
Obviously, there are still some things that could be improved. It would be much more elegant to have a Table Valued Function instead of the scalar function that returns an array which needs to be exploded afterwards. However, this is not yet possible in Fabric but will hopefully come soon.
This technique can also be applied to any other APIs that expose data. The most challenging part is usually the authentication but Fabric’s mssparkutils.credentials make it pretty easy for us to do this.
Pingback: Querying the Power BI REST API from Fabric Spark – Curated SQL
Hi Gerhard, thanks for your post. Where do I put spark.sql(f”SET token={pbi_access_token}”) ? When I use it in a notebook with PySpark Python or SQL I get error messages.
Regards
Tom
thats Python/PySpark code
in my example I used a Python/PySpark notebook
whenever I used SQL, I used the %%sql notebook magic
I’m running into the same issue. When I run the 2nd line of code spark.sql(f”SET token={pbi_access_token}”), I get an error.
NameError: name ‘pbi_access_token’ is not defined
sorry, seems like there was some copy&paste error on my side where I mixed up some variable names.
I fixed the code and it should work again now
That did the trick! Thank you so much Gerhard. As a long-time Power BI user and no-time pyspark user, this is amazing.
As a data science student I’m not sure how I can use this?
to work with SQL using power BI data or vice versa?
Any tips is appreciated. Thanks for sharing.
The idea is to simply query Power BI metadata which is only exposed via the REST API using simple SQL statements instead of writing the API calls on your own
there are some use-cases for monitoring and operations I would say and for quick exploration of your PBI tenant
Do you have some examples of how to use the REST API to get Datasets outside of your Org and pull them in to be used as dataflows?
so do you want to query the Power BI metadata from a different org or e.g. send a DAX query to a dataset that resides in a different org?
either way, the most challenging part will probably be authentication. I dont know if this is supported out of the box./
What you can try though is replacing /myorg/ in your API calls with /
You will still need to get an access token though and to be honest I am not quite sure how to do that for remote tenants
We pull in data from other organisations, normally read account on the DB is fine but API’s are being pushed and I am really struggling with the REST API and how I can use it for those DBs that will not give me DB access and want me to use API.
Thanks for the ideas, i will give it a play
guess this very much differs from what this blog post is about
if I understood correctly, you want to connect from Power BI to those new REST APIs provided by the other organisations. Then you need to stick to the authentication their REST APIs provide
Looking at the above I am thinking it must also be possible to get the activity events in this way, but I do not really understand what I need to change to the code to access these, can you maybe explain? Would be much appreciated!
do you mean this endpoint?
https://learn.microsoft.com/en-us/rest/api/power-bi/admin/get-activity-events
technically, this should work:
SELECT explode(pbi_api_udf(‘/admin/activityevents?startDateTime=”2023-09-19T00:55:00.000Z”&endDateTime=”2023-09-19T23:55:00.000Z”’, ‘${token}’)) AS workspace
but the token that was generated by mssparkutils.credentials.getToken() unfortunately does not work with the admin APIs as they require different permissions as stated in the docs
Hi Gerhard,
This is a great blogpost. Do you know if there is an equivalent token generation call for Admin API access if the user is an admin? Thanks
I tried (so did you I guess) and the Admin APIs did not work
Until now I have not found a way to make it work with the Admin APIs as all of them require the scopes Tenant.Read.All or Tenant.ReadWrite.All (https://learn.microsoft.com/en-us/rest/api/power-bi/admin/groups-get-group-as-admin#required-scope) and `getToken()` does not include those as it seems
Can an AppID/ClientSecret be used? Or only OAUTH?
Darren Gosbell describes this in his blog – thats where the original idea for this blog post came from
https://darren.gosbell.com/2023/06/calling-a-power-bi-rest-api-from-a-fabric-notebook/
I am so sorry, above comment lost identation and also lost a mention to insert Darren Gosbell’s code to be able to call admin APIs, removing only the “pip install” line because it resets the session. Darren Gosbell’s code would be inserted above that cell:
spark.sql(f”SET pbi_admin_token={access_token}”)
can you update your other comment to also include Darren Gosbell’s code so its easier for others to use it
I think its not quit clear which part of his code exactly you are referring to
Great! Thank you very much!
If anyone is interested, please see code below to call activityevents with pagination. Each — represents one notebook cell. Replace [tab] with identation.
%pip install azure.identity
—
pbi_access_token = mssparkutils.credentials.getToken(“https://analysis.windows.net/powerbi/api”)
spark.sql(f”SET pbi_access_token={pbi_access_token}”)
—
#function pbi_api modified to handle other arrays different than “value” and pagination
import requests
# make sure to support different versions of the API path passed to the function
def get_api_path(path: str) -> str:
[tab]base_path = “https://api.powerbi.com/v1.0/myorg/”
[tab]base_items = list(filter(lambda x: x, base_path.split(“/”)))
[tab]path_items = list(filter(lambda x: x, path.split(“/”)))
[tab]index = path_items.index(base_items[-1]) if base_items[-1] in path_items else -1
[tab]return base_path + “/”.join(path_items[index+1:])
# call the api_path with the given token and return the list in the “value” property
def pbi_api(api_path: str, token: str, jsonitem: str = “value”) -> object:
[tab]continuationUri = “”
[tab]continuationToken = “”
[tab]continua = True
[tab]countloop = 1
[tab]currentpath = get_api_path(api_path)
[tab]values = []
[tab]while(continua):
[tab][tab]#print(f”countloop={countloop}————————————————————–“)
[tab][tab]result = requests.get(currentpath, headers = {“authorization”: “Bearer ” + token})
[tab][tab]if not result.ok:
[tab][tab][tab]return [{“status_code”: result.status_code, “error”: result.reason}]
[tab][tab]json = result.json()
[tab][tab]#if not jsonitem in json:
[tab][tab]# return []
[tab][tab]valuestemp = json[jsonitem]
[tab][tab]for value in valuestemp:
[tab][tab][tab]if “id” in value:
[tab][tab][tab][tab]value[“apiPath”] = f”{api_path}/{value[‘id’]}”
[tab][tab][tab]else:
[tab][tab][tab][tab]value[“apiPath”] = f”{api_path}”
[tab][tab]values += valuestemp
[tab][tab]if “continuationUri” in json and json[“continuationUri”] is not None:
[tab][tab][tab]continuationUri = json[“continuationUri”]
[tab][tab][tab]#print(f”VAR continuationUri={continuationUri}”)
[tab][tab][tab]currentpath = continuationUri
[tab][tab]else:
[tab][tab][tab]continua = False
[tab][tab]if “continuationToken” in json and json[“continuationToken”] is not None:
[tab][tab][tab]continuationToken = json[“continuationToken”]
[tab][tab][tab]#print(f”VAR continuationToken={continuationToken}”)
[tab][tab]countloop = countloop + 1
[tab][tab]if countloop > 1000:
[tab][tab][tab]return [{“status_code”: -1, “error”: “Something is wrong!”}]
[tab]return values
—
import pyspark.sql.functions as F
import pyspark.sql.types as T
# schema of the function output – an array of maps to make it work with all API outputs
schema = T.ArrayType(
[tab]T.MapType(T.StringType(), T.StringType())
)
# register the function for PySpark
pbi_api_udf = F.udf(lambda api_path, token: pbi_api(api_path, token), schema)
# register the function for SparkSQL
spark.udf.register(“pbi_api_udf”, pbi_api_udf)
—
#register another function modified to handle other arrays different than “value”
import pyspark.sql.functions as F
import pyspark.sql.types as T
# schema of the function output – an array of maps to make it work with all API outputs
schema = T.ArrayType(
[tab]T.MapType(T.StringType(), T.StringType())
)
# register the function for PySpark
pbi_api_udf2 = F.udf(lambda api_path, token, jsonitem: pbi_api(api_path, token, jsonitem), schema)
# register the function for SparkSQL
spark.udf.register(“pbi_api_udf2”, pbi_api_udf2)
—
%%sql
SELECT explode(pbi_api_udf(‘/groups’, ‘${pbi_access_token}’)) as workspace
—
Insert here Darren Gosbell’s code to be able to call admin APIs, removing only the “pip install” line because it resets the session
—
spark.sql(f”SET pbi_admin_token={access_token}”)
—
%%sql
SELECT explode(pbi_api_udf(‘admin/capacities/refreshables?$top=200’, ‘${pbi_admin_token}’)) AS refreshables
—
%%sql
–Note: it supports only 1 day at a time
SELECT explode(pbi_api_udf2(“/admin/activityevents?startDateTime=’2023-10-18T00:00:00’&endDateTime=’2023-10-18T23:59:59′”, ‘${pbi_admin_token}’, ‘activityEventEntities’)) AS atividades
—
Great! Thank you very much!
If anyone is interested, please see code below to call activityevents API with pagination.
Gerhard, could you please delete my previous comments? I am sorry for the various comments, I had to adjust some code due to the blog comment engine automatic formatting.
Please note in the code below:
1) Each “—” below represents one notebook cell, so split the code in multiple cells.
2) Replace “[tab]” below with proper identation, because blog comment engine removes all identation.
—
%pip install azure.identity
—
import pyspark.sql.functions as F
import pyspark.sql.types as T
import json, requests, pandas as pd
import datetime
from azure.identity import ClientSecretCredential
import requests
—
# if you need to call admin APIs, then you have to obtain admin token:
# Darren Gosbell’s code to be able to call admin APIs:
#########################################################################################
# Read secretes from Azure Key Vault
#########################################################################################
key_vault = “https://dgosbellKeyVault.vault.azure.net/”
tenant = mssparkutils.credentials.getSecret(key_vault , “FabricTenantId”)
client = mssparkutils.credentials.getSecret(key_vault , “FabricClientId”)
client_secret = mssparkutils.credentials.getSecret(key_vault , “FabricClientSecret”)
# if you dont have secrets in Azure Key Vault, which is not recommended by the way, simply fill the variables below:
#tenant = “???”
#client = “???”
#client_secret = “???”
#########################################################################################
# Authentication (for admin APIs)
#########################################################################################
# Generates the access token for the Service Principal
api = ‘https://analysis.windows.net/powerbi/api/.default’
auth = ClientSecretCredential(authority = ‘https://login.microsoftonline.com/’, tenant_id = tenant, client_id = client, client_secret = client_secret)
access_token = auth.get_token(api)
access_token = access_token.token
print(‘\nSuccessfully authenticated.’)
#########################################################################################
# If you would like to test, then you can call Get Refreshables
#########################################################################################
#base_url = ‘https://api.powerbi.com/v1.0/myorg/’
#header = {‘Authorization’: f’Bearer {access_token}’}
#refreshables_url = “admin/capacities/refreshables?$top=200”
#refreshables_response = requests.get(base_url + refreshables_url, headers=header)
#print(refreshables_response.content)
—
#if you dont need to call admin APIs, then you can obtain access token instead of admin token:
#access_token = mssparkutils.credentials.getToken(“https://analysis.windows.net/powerbi/api”)
—
spark.sql(f”SET pbi_access_token={access_token}”)
—
#function pbi_api modified from original article to handle other json items different than “value” and also to handle pagination.
# make sure to support different versions of the API path passed to the function
def get_api_path(path: str) -> str:
[tab]base_path = “https://api.powerbi.com/v1.0/myorg/”
[tab]base_items = list(filter(lambda x: x, base_path.split(“/”)))
[tab]path_items = list(filter(lambda x: x, path.split(“/”)))
[tab]index = path_items.index(base_items[-1]) if base_items[-1] in path_items else -1
[tab]return base_path + “/”.join(path_items[index+1:])
# call the api_path with the given token and return the list in the “value” property
def pbi_api(api_path: str, token: str, jsonitem: str = “value”) -> object:
[tab]continuationUri = “”
[tab]continuationToken = “”
[tab]continua = True
[tab]countloop = 1
[tab]currentpath = get_api_path(api_path)
[tab]values = []
[tab]while(continua):
[tab][tab]#print(f”countloop={countloop}————————————————————–“)
[tab][tab]result = requests.get(currentpath, headers = {“authorization”: “Bearer ” + token})
[tab][tab]if not result.ok:
[tab][tab][tab]return [{“status_code”: result.status_code, “error”: result.reason}]
[tab][tab]json = result.json()
[tab][tab]#if not jsonitem in json:
[tab][tab]# return []
[tab][tab]valuestemp = json[jsonitem]
[tab][tab]for value in valuestemp:
[tab][tab][tab]if “id” in value:
[tab][tab][tab][tab]value[“apiPath”] = f”{api_path}/{value[‘id’]}”
[tab][tab][tab]else:
[tab][tab][tab][tab]value[“apiPath”] = f”{api_path}”
[tab][tab]values += valuestemp
[tab][tab]if “continuationUri” in json and json[“continuationUri”] is not None:
[tab][tab][tab]continuationUri = json[“continuationUri”]
[tab][tab][tab]#print(f”VAR continuationUri={continuationUri}”)
[tab][tab][tab]currentpath = continuationUri
[tab][tab]else:
[tab][tab][tab]continua = False
[tab][tab]if “continuationToken” in json and json[“continuationToken”] is not None:
[tab][tab][tab]continuationToken = json[“continuationToken”]
[tab][tab][tab]#print(f”VAR continuationToken={continuationToken}”)
[tab][tab]countloop = countloop + 1
[tab][tab]if countloop > 1000:
[tab][tab][tab]return [{“status_code”: -1, “error”: “Something is wrong!”}]
[tab]return values
—
# schema of the function output – an array of maps to make it work with all API outputs
schema = T.ArrayType(
[tab]T.MapType(T.StringType(), T.StringType())
)
# register the function for PySpark
pbi_api_udf = F.udf(lambda api_path, token: pbi_api(api_path, token), schema)
# register the function for SparkSQL
spark.udf.register(“pbi_api_udf”, pbi_api_udf)
—
#register another function modified to handle other arrays different than “value”
# schema of the function output – an array of maps to make it work with all API outputs
schema = T.ArrayType(
[tab]T.MapType(T.StringType(), T.StringType())
)
# register the function for PySpark
pbi_api_udf2 = F.udf(lambda api_path, token, jsonitem: pbi_api(api_path, token, jsonitem), schema)
# register the function for SparkSQL
spark.udf.register(“pbi_api_udf2”, pbi_api_udf2)
—
%%sql
–Test udf with non-admin API:
SELECT explode(pbi_api_udf(‘/groups’, ‘${pbi_access_token}’)) as workspace
—
%%sql
–Test udf with admin API:
SELECT explode(pbi_api_udf(‘admin/capacities/refreshables?$top=200’, ‘${pbi_access_token}’)) AS refreshables
—
%%sql
–Test udf with admin API with pagination and also returning activityEventEntities json items:
–Note: This API supports only 1 day at a time
SELECT explode(pbi_api_udf2(“/admin/activityevents?startDateTime=’2023-10-18T00:00:00’&endDateTime=’2023-10-18T23:59:59′”, ‘${pbi_access_token}’, ‘activityEventEntities’)) AS atividades
—
Interesting to see all the different approaches to working with the Power BI REST API in notebooks.
My attempt at calling the admin APIs (specifically the Activity Events API and dumping the results into a Delta table is here: https://github.com/klinejordan/fabric-tenant-admin-notebooks/blob/main/Fabric%20Admin%20Activities.ipynb
Have not had much like with Spark UDFs calling more complex APIs like the Scanner API as they don’t seem to be able to handle polling very well but that could just be my inexperience with Spark
indeed another great way to query the Power BI APIs from a Fabric notebook!
Pingback: how to call power bi rest apis from fabric data pipelines.
Hello! Thank you for the article!
Would u know if it is possible to read data from the semantic model in power bi SERVICE directly to databricks where I can perform some data query? Is it possible to do this with SELF API or do you know of any other ways to perform this task? Thank you!
you can try the Execute Queries API which you can also call from Databricks
https://learn.microsoft.com/en-us/rest/api/power-bi/datasets/execute-queries
the trickiest thing will probably getting the authentication to work
Hey there!
great tutorial, many thanks.
I tried to run this to get users for an app. However, the code then returns “not found”.
%%sql
SELECT pbi_api_udf(‘/apps/{app-id}/users’, ‘${pbi_access_token}’) as users
I am 100% certain, that I use the correct App ID, because when I run the code via “Try it” in the Learn Section, it returns me all users.
not sure, I am basically just running a regular GET request in the background using that token
if you specify the right app-id it should work, assuming the token is also correct of course
do any other API endpoints work?