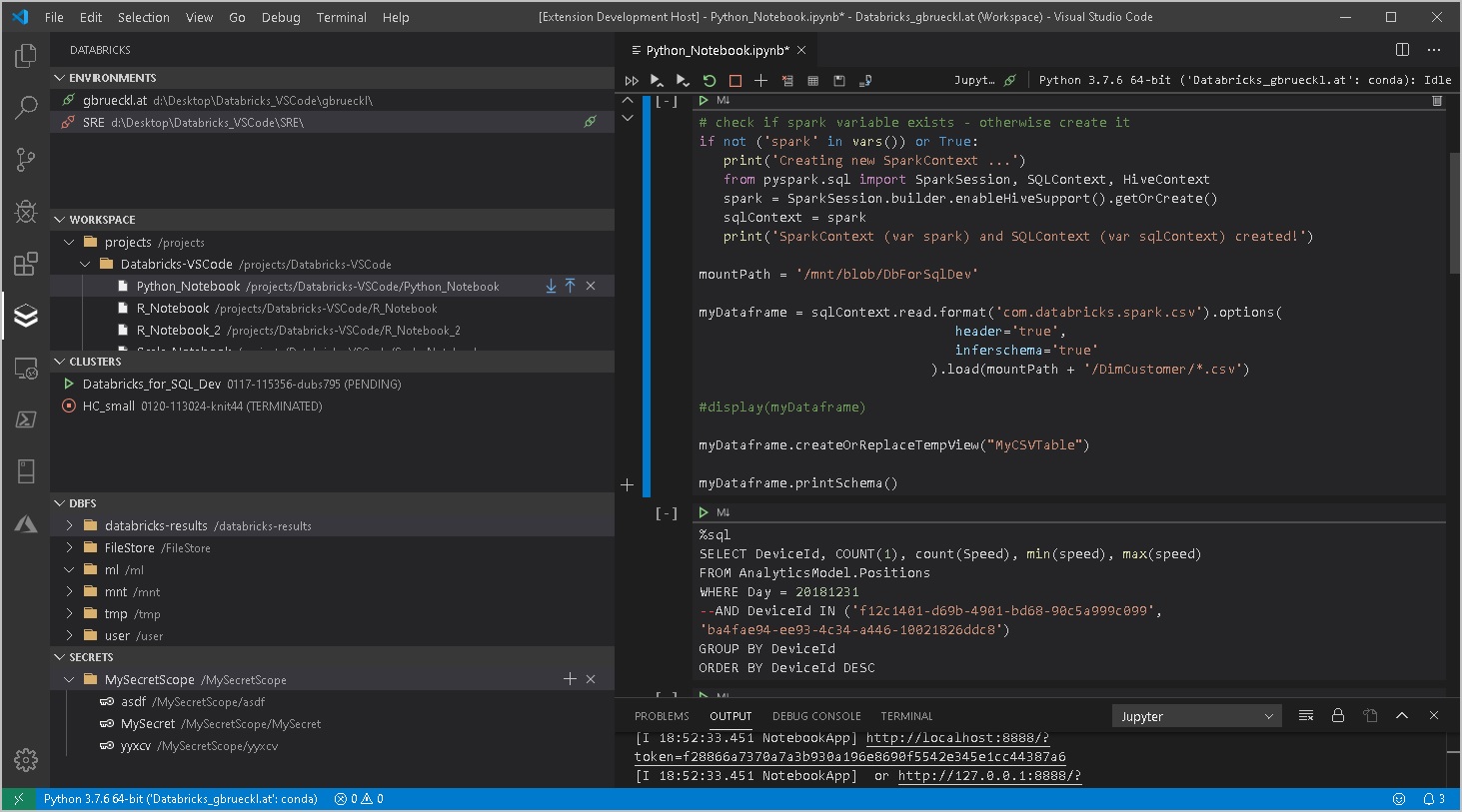
When working with Databricks you will usually start developing your code in the notebook-style UI that comes natively with Databricks. This is perfectly fine for most of the use cases but sometimes it is just not enough. Especially nowadays, where a lot of data engineers and scientists have a strong background also in regular software development and expect the same features that they are used to from their original Integrated Development Environments (IDE) also in Databricks.
For those users Databricks has developed Databricks Connect (Azure docs) which allows you to work with your local IDE of choice (Jupyter, PyCharm, RStudio, IntelliJ, Eclipse or Visual Studio Code) but execute the code on a Databricks cluster. This is awesome and provides a lot of advantages compared to the standard notebook UI. The two most important ones are probably the proper integration into source control / git and the ability to extend your IDE with tools like automatic formatters, linters, custom syntax highlighting, …
While Databricks Connect solves the problem of local execution and debugging, there was still a gap when it came to pushing your local changes back to Databricks to be executed as part of a regular ETL or ML pipeline. So far you had to either “deploy” your changes by manually uploading them via the Databricks UI again or write a script that uploads it via the REST API (Azure docs).
NOTE: I also published a PowerShell module that eases the automation/scripting of these tasks also as part of CI/CD pipeline. It is available from the PowerShell gallery DatabricksPS and integrates very well with this VSCode extension too!
However, this is not really something you would call a “seamless experience” so I also started working on an extension for Visual Studio Code to work more efficiently with Databricks. It has been in the VS Code gallery (Databricks VSCode) for about a month now and I received mostly positive feedback so far. Now I am at a stage where I want to get more people to use it – hence this blog post to announce it officially. The extension is currently published under GPLv3 license and is free to use for everyone. The GIT repository is also linked in the VS Code gallery if you want to participate or have any issues with the extension.

It currently supports the following features:
- Workspace browser
- Up-/download of notebooks and whole folders
- Compare/Diff of local vs online notebook (currently only supported for raw files but not for notebooks)
- Execution of local code and notebooks against a Databricks Cluster (via Databricks-Connect)
- Cluster manager
- Start/stop clusters
- Script cluster definition as JSON
- Job browser
- Start/stop jobs
- View job-run history + status
- Script job definition as JSON
- Script job-run output as JSON
- DBFS browser
- Upload files
- Download files
- (also works with mount points!)
- Secrets browser
- Create/delete secret scopes
- Create/delete secrets
- Support for multiple Databricks workspaces (e.g. DEV/TEST/PROD)
- Easy configuration via standard VS Code settings
More features to come in the future but these will be mainly based on the requests that come from users or my personal needs. So your feedback is highly appreciated – either directly here or using the feedback section in the GIT repository.
I will also write some follow up post to show you how to work in the most efficient way using this new VSCode extension in combination with your Databricks workspace so stay tuned!
VS Code gallery: paiqo.Databricks-VSCode
Github repository: Databricks-VSCode
Pingback: Developing for Databricks with VS Code – Curated SQL
Great work, Gerhard! I’ve been using it for some weeks now and it really speeds up development. Have you seen the ‘https://github.com/databrickslabs/jupyterlab-integration’ project? Do you think it would be possible to have something similar on vscode? From my perspective it is just a matter of creating an extra step between the jupyterlab backend and vscode, but of course that’s easier said than done.
I have not had a look at the jupyterlab integration yet but as yeid, I should be possible to configure it in jupyter and then use vscode with the python extension to connect to.
But that’s outside of the scope of this extension (as is Databricks-connect)
I’m having issues seeing my databricks connections and workspaces and such in the Databricks window on the VS Code interface. Have I not set something up right in the settings? I entered the default databricks API root as https://westus2.azuredatabricks.net. Is there something else I need to enter here? What am I missing?
You need to set at least the mandatory settings: api root URL, personal access token, local sync folder and the display name in the VS Code settings
Then it should work
Do you get any error messages or warnings?
No, but I enter the information and then it disappears when I refresh the workspace or connections area. There are no errors but nothing gets entered in the areas for Databricks on the left side of VS Code. I’m starting to think that there is a problem with the extension.
I’ve done all that and it just disappears on me between refreshes of the environment. There are no errors are anything other than saying I need to enter a mandatory value which I do and then it disappears.
Any news about how I might use your Databricks-VSCode extension? I’ve tried everything I know and I still can’t seem to get it to work. I’ve entered all of the mandatory info and it still just seems to disappear and I don’t get a connection. Please advise.
Have you tried saving you VSCode session as VSCode workspace? Then the extension-specific settings will be associated with the VSCode workspace
No, I haven’t tried that because the current solution I am working with does not have an associated workspace. I suppose I could add one and then try it but why is it associated with a workspace? Shouldn’t it just work whether you are in a workspace or not? Thanks!
It should but I remember a bug in the current version.
Using vscode workspaces it should work
Yeah, I am now seeing the cluster that I initially wanted to connect to but it is not displaying the jobs or the workspaces or DBFS info.
Hmm, that’s weird, you should see all or nothing unless you use an access token which only has access to clusters
Do you see any error messages in the dedicated log provider (there is extensive logging)
No, but once I refreshed each section I began to see information as I should. So it appears to be working finally. Thanks for your help. It looks like adding a workspace did the trick.
I am getting a not implemented error when I am trying to refresh the jobs. And clusters are not iterable error when doing so for clusters. Also I can’t see my objects in any of the folders even after refreshing.
I read your reply to Brian but can’t really figure out how to do it.
Kindly help!!
can you please file an issue in the git-repo https://github.com/paiqo/Databricks-VSCode/issues
please also add a screenshot and the version-number
i will follow up there then
regards,
-gerhard
How do you connect and run your code on the cluster through the IDE VS Code?
I can connect to my Cluster and See workspaces and data, I can even start clusters, How do you connect a workspace to the cluster to then execute SQL code for example?
Databricks-Connect is the solution here – just Google for it 🙂
I’ve never been able to get db-connect to work. Perhaps you could go over the steps to make it work on a Windows 10 machine in your next blog.
here are some good resources:
https://datathirst.net/blog/2019/3/7/databricks-connect-finally
https://datathirst.net/blog/2019/4/20/setup-databricks-connect-on-windows
or all of Simons blogs on this topic:
https://datathirst.net/blog/tag/Databricks-Connect
Hi
I have managed to configure it.
We have few notebooks already stored (working successfully) in Azure Databricks workspace but when I tried to do two tasks then I got below issues:
1. Run the cluster from VS Code then error message appears:
Cluster [cluster_name] is in unexpected state Running
but still can see it running in Clusters pane inside VS Code.
2. When I tried to run a cell in notebook then error appears:
NameError: name ‘dbutils’ is not defined
The same cell works fine on the Azure Databricks workspace.
Could you please provide your inputs? Thanks
1) always showing the correct cluster state in VS Code is kind of tricky. I would need to query the Cluster API frequently to get the latest state is it could also be stopped by the UI or by someone else using the REST API.
if you experience issues with cluster states, I would recommend refeshing the Clusters tab manually using the refresh icon at the right top
2) so this link should help for dbutils when using databricks-connect:
https://docs.databricks.com/dev-tools/databricks-connect.html#access-dbutils
regards,
-gerhard
That’s really cool! Although, do you have any way of handling notebook workflows from your local IDE? We are trying to make it easier to work with databricks for some devs who are more used to the “old ways of working” and that’s the main obstacle atm.
Thanks!
Tomasz
what exactly do you mean with “notebook workflows”?
Hi there! This looks great!
One feature I’m missing would be showing MLflow experiments (not sure of how difficult would be to implement). This could be a life changer, to be honest, it would be great if you could add it to the extension 😀
Hi Jose,
I agree that it would make sense to also have ML Flow in VS Code.
But it would make more sense to have it as a separate extension as ML Flow is an open standard which is supported by Databricks but also a lot of other services (e.g. Azure ML Service)
maybe we at paiqo pick this up in the future but no commitments yet
-gerhard
Hi again, Gerhard. Thanks for the quick response.
I think you are right in that regard, as MLflow can be used without Databricks. However, since there is a MLflow service integrated with the Databricks workspace, with its own tab in the GUI, I don’t know if would make sense to show them in the extension workspace browser
I agree from an end-user perspective, but it makes much more sense to create a generic ML Flow extension that works with all services
I guess if we create this extension in the future, we will create a generic one
Can’t wait to give it a try, then 😀
Hola, felicidades por esta extensión es fantástica, Sin embargo estoy teniendo problemas al visualizar mi archivo .ipynb en formato de celdas, obtengo el siguiente error: “Opening local cached file. To open most recent file from Databricks, please manually download it first!”. Agradecería me pudieras guiar a solucionar mi problema. Un abrazo desde Perú.
sorry, I do not really speak Spanish or Portuguese
you you post your question in English please?
-gerhard
Hi Gerhard,
your extension is awesome. In help with that we should be able to build a rapidly development process.
But I have a question :).
On the VSC marketplace page you wrote:
“The downloaded files can then be executed directly against the Databricks cluster if Databricks-Connect is setup correctly…”
Well I guess I did it correctly :).
But what about Notebook Commands in a cell like that:
%pip install /dbfs/abc/blah.whl
Currently if I’m executing a cmd like this, I’m getting a error:
Processing c:\dbfs\abc\blah.whl
Note: you may need to restart the kernel to use updated packages.
WARNING: Requirement ‘/dbfs/abc/blah.whl’ looks like a filename, but the file does not exist
ERROR: Could not install packages due to an OSError: [Errno 2] No such file or directory: ‘C:\\dbfs\\dbfs\\blah.whl’
Well, imho the pip cmd won’t be send to the databricks cluster. What do you mean?
Thanks in advance,
Markus
To make this work you would need to add a new magic (%xxx) to the ipython/notebook extension i guess and configure it accordingly. But definitely something that is out of scope of my extension which is – whit regards to notebooks – only for up- and downloading notebooks. What you do locally with them is totally up to you.
Usually Databricks-connect is used to work with them but i do not think it supports this either
Ok, thanks!
For my clarification, with “new magic” you mean, that I have to implement a new feature, right?
What does it mean, if you write “configure it accordingly”?
Markus
Magics are the tags at the top/beginning of a notebook cell – e.g. %sql, %python or %pip
Some of them are supported out of the box in Python in VS Code but you can also create your own
https://scipy-ipython.readthedocs.io/en/latest/interactive/magics.html
Pingback: Databricks VSCode Extension – Release v1.0! – Gerhard Brueckl on BI & Data