In my past years as a consultant for Microsoft BI I had to deal with financial models quite a lot. They are usually small in size but very complex in terms of calculations like currency conversion, margin-calculations, benchmarks and so on. Another topic I came across very frequently was consolidation and intercompany eliminations. Recently I had to deal with this topic again and thought of how this could be solved in PowerPivot/DAX.
First of all a little background information on what consolidation and intercompany eliminations are. In bigger companies with several subsidiaries those subsidiaries are usually structured in some way – e.g. by legal entity, by country etc..
Here is a little example of a corporate group called “My Whole Company” with subsidiaries in Germany, France, USA and Canada, structured by geography:

These companies also make business with each other and also with external customers. The French Company and the Canadian Company sell something to the Germany Company, US Company sells goods to the Canadian Company and French Company and so on.
To get a consolidated value for higher nodes (e.g. Europe), transactions between companies within Europe have to be eliminated. Otherwise sales within Europe would be aggregated up even though the goods never left Europe and therefor cannot be added to Europe’s sales.
(I am not a financial guy so I focused on the technical stuff rather then on the business backgrounds. This whole example just demonstrates a general approach to solve this issue technically.)
Our fact-table contains columns for the SenderCompany, ReceiverCompany and Value:
| SenderID | ReceiverID | Value |
| FR | GER | 100 |
| CAN | GER | 50 |
| GER | EXTERNAL | 70 |
| USA | CAN | 30 |
| USA | FR | 10 |
| USA | EXTERNAL | 90 |
| CAN | USA | 50 |
| CAN | EXTERNAL | 10 |
For our Sender and Receiver-Table we can use the same source-table (details on this follow):
| SenderID | ParentSenderID | Name |
| TOT | My Whole Company | |
| EUROPE | TOT | Europe |
| GER | EUROPE | Germany Company |
| FR | EUROPE | French Company |
| NA | TOT | North America |
| USA | NA | US Company |
| CAN | NA | Canadian Company |
| EXTERNAL | EXTERNAL |
Note that we use a parent-child hierarchy here as most financial applications use them to represent hierarchical structures. The parent-child hierarchy is resolved using PATH(), PATHITEM() and LOOKUPVALUE() functions as described here by Alberto Ferrari. The final table is added twice to our model, for Sender and Receiver:

(for simplicity I removed all other columns of the fact-table and their corresponding dimension-tables).
The next step is to implement the business logic for consolidation and intercompany elimination. From the description above we can break this logic down into smaller pieces. To get a consolidated value, we have to:
- Select only Senders below the currently selected SenderHierarchy-Node
- Select only Receivers, that are NOT below the ReceiverHierarchy-Node that is equal to the currently selected SenderHierarchy-Node
- Sum up the remaining fact-rows
Value_SUM:=SUM(Facts[Value])
Value_Internal:=
CALCULATE(
[Value_SUM],
FILTER(
'Receiver',
CONTAINS(
'Sender',
'Sender'[SenderID],
'Receiver'[ReceiverID])))
The Receiver-table is filtered using the CONTAINS-function. As FILTER operates row-by-row, each ‘Receiver’[ReceiverID] is checked whether its value can also be found in the currently selected SenderIDs. In T-SQL this would be similar to:
SELECT SUM([Value]
FROM Facts
INNER JOIN Sender
ON Facts.SenderID = Sender.SenderID
INNER JOIN Receiver
ON Facts.ReceiverID = Receiver.ReceiverID
WHERE Receiver.ReceiverID IN (SELECT SenderID
FROM Sender
WHERE Level2='Europe')
AND Sender.Level2 = 'Europe'
Once you understand how the T-SQL, the DAX-calculation should also be clear.
Value_External:=
CALCULATE(
[Value_SUM],
FILTER(
'Receiver',
NOT(
CONTAINS(
'Sender',
'Sender'[SenderID],
'Receiver'[ReceiverID]))))
And this is already our final calculation to eliminate intercompany sales and get a consolidated value for any Sender-node we select!

Europe has total sales of 170 of which 100 have been internal (FR to GER) and 70 have been external (GER to EXTERNAL). North America has a total value of 240 of which 80 have been internal (USA to CAN 30 and CAN to USA 50) and 160 have been sold external to either Europe or external customers.
The calculation can be further simplified in terms of usability. You may already realized that we did not refer to our hierarchy within any of our calculation. We always used the leaf-level (SenderID/ReceiverID) to calculated our values. To solve the original problem in a multidimensional model we had to create a Receiver-dimension and select/deselect members based on the current selection in the Sender-hierarchy. This is not necessary anymore as we only use leaf-elements in our calculation. So we do not need a Receiver-hierarchy and further also no Receiver-table in our PowerPivot-model as we already have the ReceiverID in our Facts-table:
Value_External_Facts:=
CALCULATE(
[Value_SUM];
FILTER(
'Facts';
NOT(
CONTAINS(
'Sender';
'Sender'[SenderID];
'Facts'[ReceiverID]))))
There may also be reasons that the user wants to select the Receiver-Node on its own. For example to see sales from European to external customers (EXTERNAL). To do this you have to adopt the calculation as follows:
Value_Selected:=CALCULATE(
[Value_SUM];
FILTER(
ALL(Receiver);
NOT(
CONTAINS(
'Receiver';
'Receiver'[ReceiverID];
'Receiver'[ReceiverID]))))
This calculation may look strange on first sight but does exactly what we need. It removes all filters from the Receiver-table and applies a new filter that is the opposite of the currently existing filter using a combination of NOT() and CONTAINS(). The 3rd parameter of the CONTAINS-function always refers to the row-context of the FILTER-function whereas the 1st and the 2nd parameter are always based on the current query-context.
These are the results:
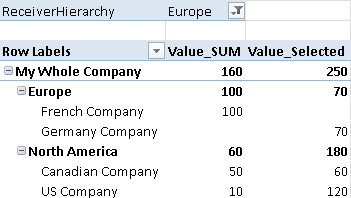
You could also use the Value_SUM-calculation to get the opposite value – what has been sold from the current Sender-node to any Receiver located in Europe. Our Canadian Company for example has sold 50 to GER which is below Europe and 60 to companies outside Europe – in this case 50 to USA and 10 to EXTERNAL.
As you can see using DAX makes these kind of calculations very easy compared to multidimensional models. An other important aspect is that financial models are usually very small and therefor should fit into memory very easily. Also the independence of hierarchies is an important aspect here.
You can also download the Excel-Workbook with the sample-calculations here:
Consolidation.xlsxUPDATE:
In Part2 I will show how to handle multiple parallel hierarchies.




![PT_Warehouse_IsValid_thumb[2]](https://blog.gbrueckl.at/wp-content/uploads/2012/02/pt_warehouse_isvalid_thumb2.jpg "PT_Warehouse_IsValid_thumb[2]")
![PT_Amount_by_Warehouse_thumb[1]](https://blog.gbrueckl.at/wp-content/uploads/2012/02/pt_amount_by_warehouse_thumb1.jpg "PT_Amount_by_Warehouse_thumb[1]")
![PT_Amount_by_Warehouse_SingleDate_thumb[2]](https://blog.gbrueckl.at/wp-content/uploads/2012/02/pt_amount_by_warehouse_singledate_thumb2.jpg "PT_Amount_by_Warehouse_SingleDate_thumb[2]")