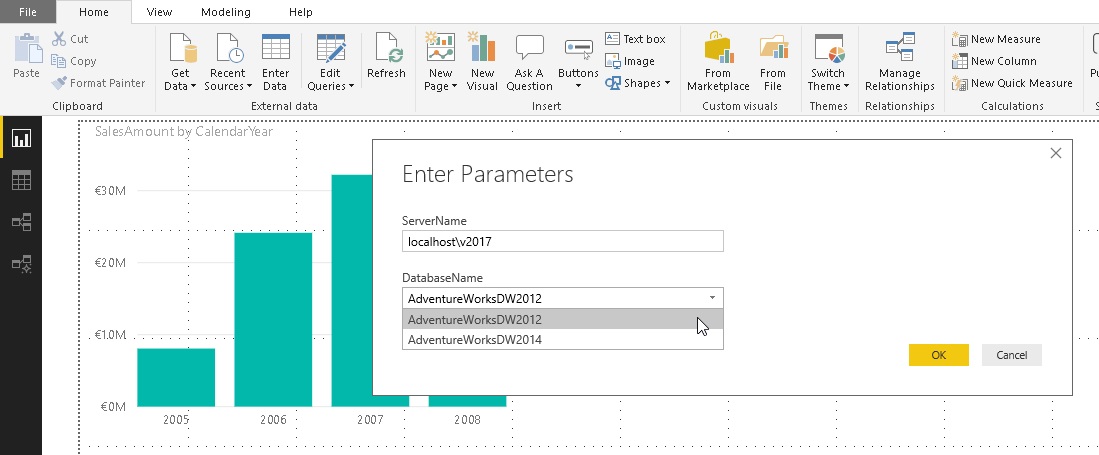
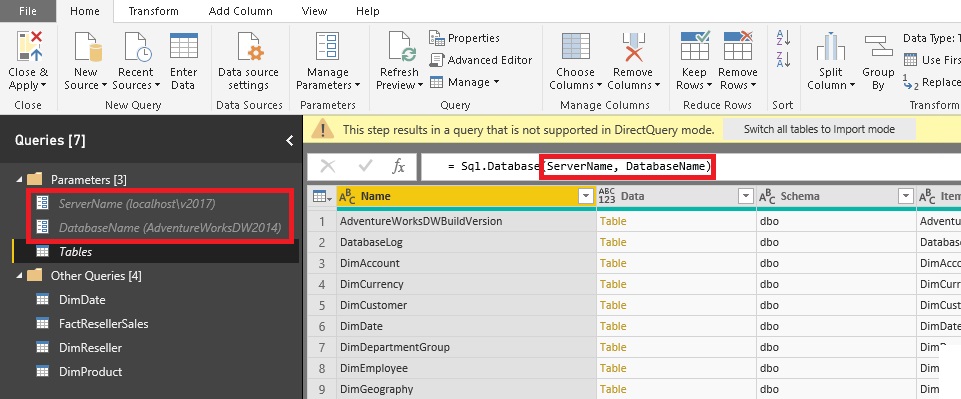
In my previous post I showed how you can use Microsoft Power BI to create a Data Virtualization layer on top of multiple relational data sources querying them all at the same time through one common model. As I already mentioned in the post and what was also pointed out by Adam Saxton (b, t) in the comments is the fact, that this approach can cause serious performance problems at the data source and also on the Power BI side. So in this post we will have a closer look on what actually happens in the background and which queries are executed when you join different data sources on-the-fly.
We will use the same model as in the previous post (you can download it from there or at the end of this post) and run some basic queries against it so we can get a better understanding of the internals.
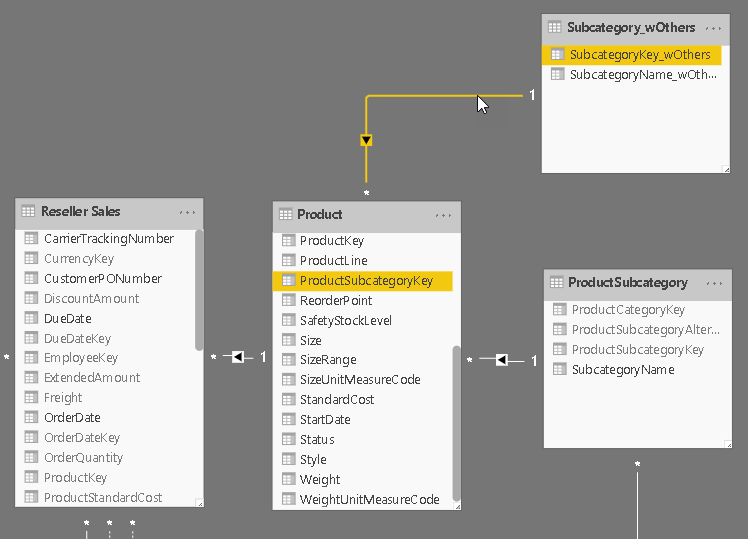
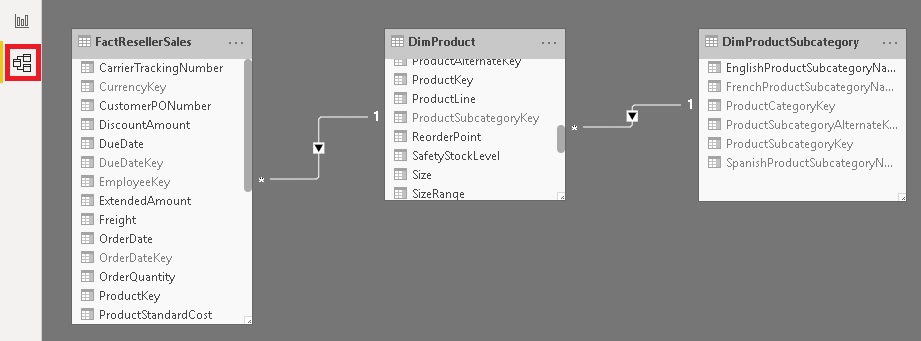
Here is our relationship diagram again as a reference. Please remember that each table comes from a different SQL server:
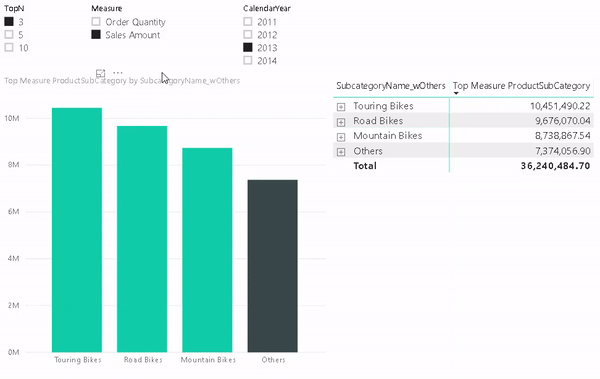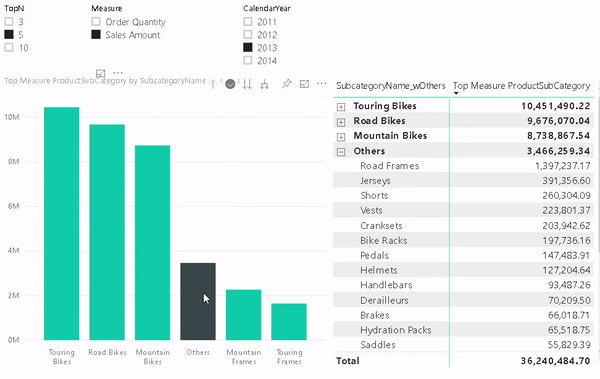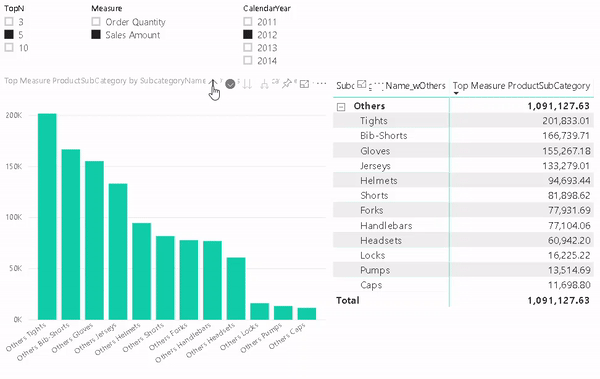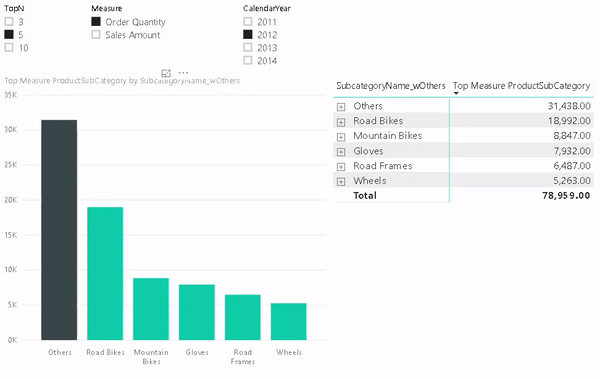
In our test we will simply count the number of products for each Product Subcategory:
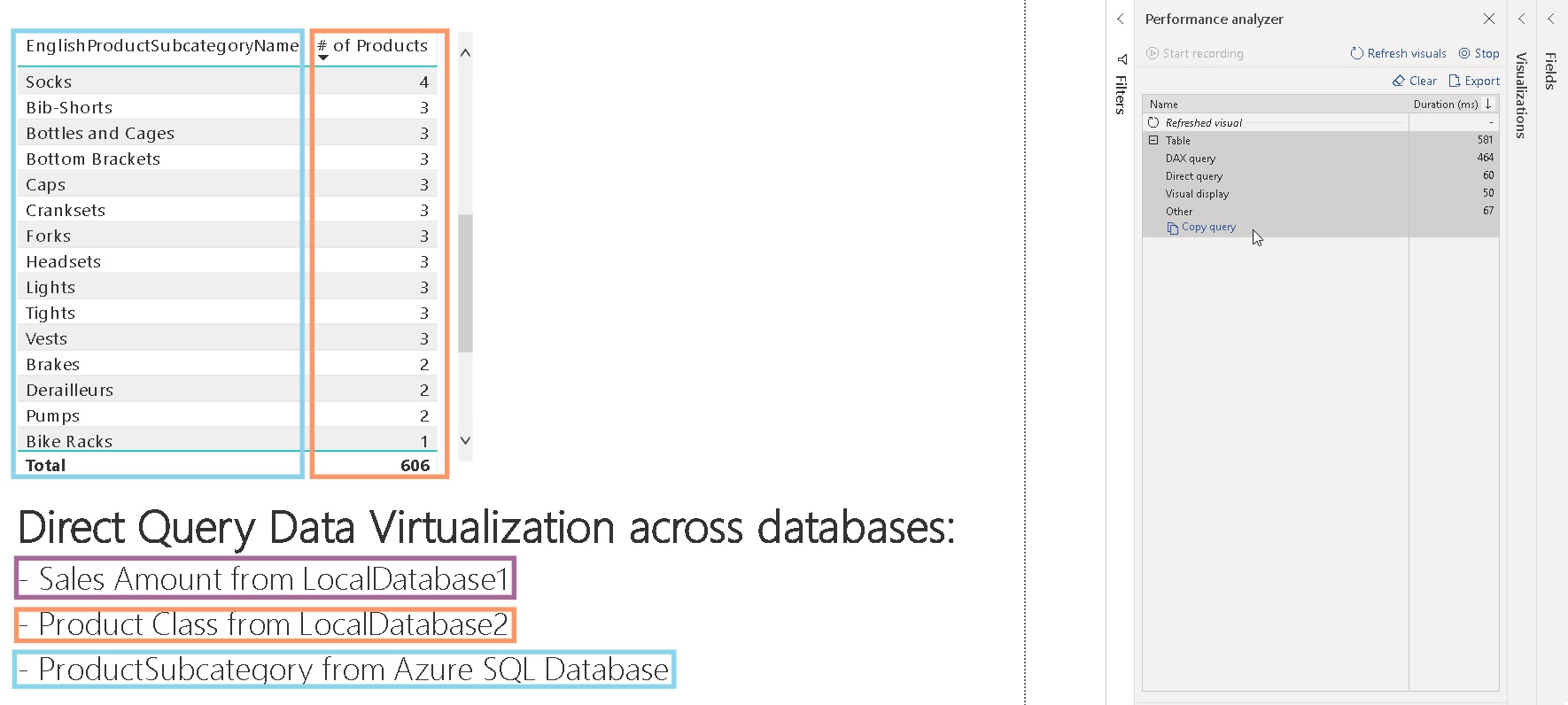
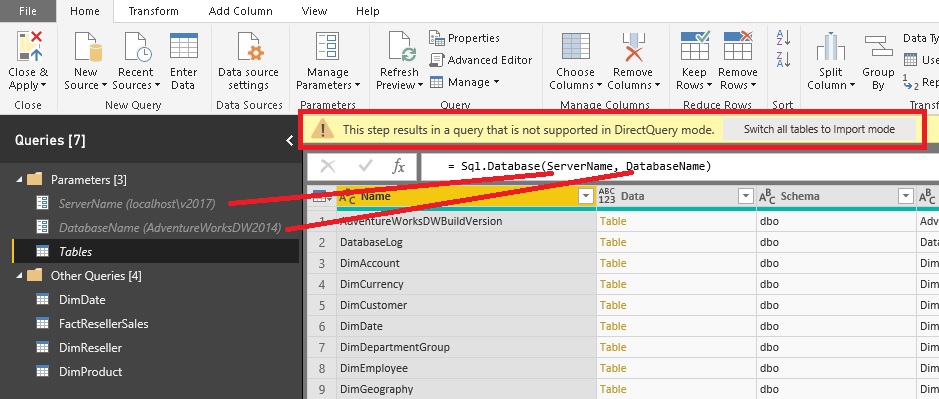
Even though this query only touches two different data sources, it is a good way to analyze the queries sent to the data sources. To track these queries I used the built-in Performance Analyzer of Power BI desktop which can be enabled on the “View”-tab. It gives you detailed information about the performance of the report including the actual SQL queries (under “Direct query”) which were executed on the data sources. The plain text queries can also be copied using the “Copy queries” link at the bottom. In our case 3 SQL queries were executed against 2 different SQL databases:
Query 1:
SELECT TOP (1000001)
[t2].[ProductSubcategoryKey],
[t2].[ProductSubcategoryName]
FROM
(
(
select
[_].[ProductSubcategoryKey] as [ProductSubcategoryKey],
[_].[ProductSubcategoryAlternateKey] as [ProductSubcategoryAlternateKey],
[_].[EnglishProductSubcategoryName] as [ProductSubcategoryName],
[_].[SpanishProductSubcategoryName] as [SpanishProductSubcategoryName],
[_].[FrenchProductSubcategoryName] as [FrenchProductSubcategoryName],
[_].[ProductCategoryKey] as [ProductCategoryKey]
from [dbo].[DimProductSubcategory] as [_]
)
) AS [t2]
GROUP BY
[t2].[ProductSubcategoryKey],
[t2].[ProductSubcategoryName]
Result: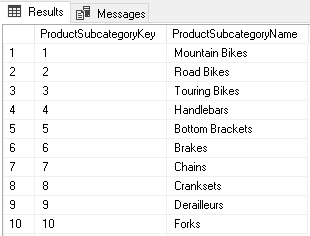
The query basically selects two columns from the DimProductSubcategory table:
- ProductSubcategoryKey – which is used in the join with DimProduct
- ProductSubcategoryName – which is the final name to be displayed in the visual
The inner sub-select (line 7-14) represents the original Power Query query. It selects all columns from the DimProductSubcategory table and renames [EnglishProductSubcagetoryName] to [ProductSubcategoryName] (line 10). Any other Power Query steps that are supported in direct query like aggregations, groupings, filters, etc. would also show up here.
Query 2 (shortened):
SELECT TOP (1000001)
[semijoin1].[c67],
SUM([a0]) AS [a0]
FROM
(
(
SELECT
[t1].[ProductSubcategoryKey] AS [c29],
COUNT_BIG(*) AS [a0]
FROM
(
(
select
[$Table].[ProductKey] as [ProductKey],
[$Table].[ProductAlternateKey] as [ProductAlternateKey],
…
from [dbo].[DimProduct] as [$Table]
)
) AS [t1]
GROUP BY [t1].[ProductSubcategoryKey]
) AS [basetable0]
inner join
(
(SELECT N'Mountain Bikes' AS [c67],1 AS [c29] ) UNION ALL
(SELECT N'Road Bikes' AS [c67],2 AS [c29] ) UNION ALL
(SELECT N'Touring Bikes' AS [c67],3 AS [c29] ) UNION ALL
(SELECT N'Handlebars' AS [c67],4 AS [c29] ) UNION ALL
(SELECT N'Bottom Brackets' AS [c67],5 AS [c29] ) UNION ALL
…
(SELECT null AS [c67],null AS [c29] )
) AS [semijoin1]
on [semijoin1].[c29] = [basetable0].[c29]
)
GROUP BY [semijoin1].[c67]
(The query was shortened at line 16 and line 29 as the removed columns/rows are not relevant for the purpose of this example.)
Similar to Query 1 above, the innermost sub-select (line 13-17) in the FROM clause returns the results of the Power Query query for DimProduct whereas the outer sub-select (line 7-20) groups the result by the common join-key [ProductSubcategoryKey].
This result is then joined with a static table which is made up from hard-coded SELECTs and UNION ALLs (line 24-30). If you take a closer look, you will realize that this table actually represents the original result of Query 1! Additionally it also includes a special NULL-item (line 30) that is used to handle non-matching entries.
The last step is to group the joined tables to obtain the final results.
Query 3 (shortened):
SELECT
COUNT_BIG(*) AS [a0]
FROM
(
(
select
[$Table].[ProductKey] as [ProductKey],
[$Table].[ProductAlternateKey] as [ProductAlternateKey],
…
from [dbo].[DimProduct] as [$Table]
)
) AS [t1]
(The query was shortened at line 9 as the removed columns/rows are not relevant for the purpose of this example.)
The last query is necessary to display the correct grand total across all products and product sub-categories.
As you can see, most of the “magic” happens in Query 2. The virtual join or virtualization is done by hard-coding the results of the remote table/data source directly into the SQL query of the current table/data source. This works fine as long as the results of the remote query are small enough – both, in terms of numbers of rows and columns – but the more limiting factor is the number of rows. Roughly speaking, if you have more than thousand items that are joined this way, the queries tend to get slow. In reality this will very much depend on your data so I would highly recommend to test this with your own data!
I ran a simple test and created a join on the SalesOrderNumber which has about 27,000 distinct items. The query never returned any results and after having a look at the Performance Analyzer I realized, that the query similar to Query 2 above was never executed. I do not know yet whether this is because of the large number of items and the very long SQL query that is generated (27,000 times SELECT + UNION ALL !!!) or a bug.
At this point you may ask yourself if it makes sense to use Power BI for data virtualization or use another tool that was explicitly designed for this scenario. (Just google for “data virtualization”). These other tools may perform better even on higher volume data but they will also reach their limits if the joins get too big and, what is even more important, the are usually quite expensive.
So I think that Power BI is still a viable solution for data virtualization if you keep the following things in mind:
– keep the items in the join columns at a minimum
– use Power Query to pre-aggregate the data if possible
– don’t expect too much in terms of performance
– only use it when you know what you are doing 🙂