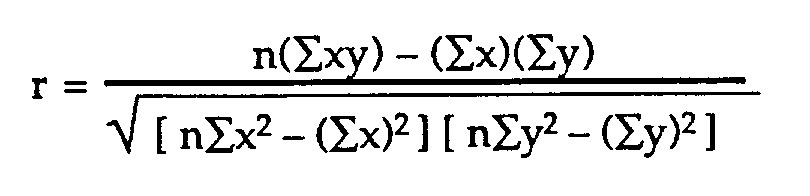Some time ago, when Microsoft released the first version of Power BI Rest API I already wrote a wrapper for C# which allowed you to map the object from the API into regular C# objects and work with them locally. However, there have been some major upgrades since then (Actually they were already announced in July 2016 but I did not find anytime to work on this again until now ). Anyway, I just published a new version of my C# wrapper on my GitHub site: https://github.com/gbrueckl/PowerBI.API.Client
To use it, you first need to create an Azure AD application and get an ApplicationID – this is very well described here or can be done directly at https://dev.powerbi.com/apps
A new PowerBI API Client object can then be created using the ApplicationID:
Basically, most of the features described in the API reference are also included in the API Wrapper. So you can now use C# to create your PowerBI model locally and deploy it to the PowerBI service! The only to keep in mind is that the dataset you create via the API can only be sourced by pushing data into it using the Push/Streaming API. As this can be quite cumbersome sometimes, I also added the functionality to publish a whole C# DataTable with basically just two lines of code to publish your reference data/dimensions:
Publish DataTable to PowerBI
// create a regular DataTable – but could also be derived from a SQL Database! DataTable dataTable = newDataTable(); /* populate the dataTable */ // create a PBI table from a regular DataTable object PBITable productsTable = newPBITable(dataTable); // publish the table and push the rows from the dataTable to the PowerBI table productsTable.PublishToPowerBI(true);
This snippet basically deploys the table structure to the PowerBI service and populates it with data from the DataTable:
For your “fact”-data you can also create single rows on your own using the PBIRow-object and publish them manually e.g. for WriteBack-scenarios:
Of course, all the features that were already supported in the first version, are still supported:
Get Embed-URLs of Reports and Tiles
List Reports, Dashboards, Datasets, …
The new version also supports Streaming and PushStreaming datasets in the same way as it does for regular Push datasets. For details on Streaming datasets please take a look at Real-time streaming in PowerBI
I recommend to explore the API on your own by simply building your first PowerBI Push/Streaming Model on your own! For the latest features and improvements please refer to the GitHub repository which will be updated frequently.
Any feedback and participation in the further development is highly appreciated and will be done via the GitHub repository.
Some time ago Microsoft released the first preview of a tool which allows you to monitor and control your Azure Data Factory (ADF). It is a web UI where you can select your Pipeline, Activity or Dataset and check its execution state over time. However, from my very personal point of view the UI could be much better, especially much clearer(!) as it is at the moment. But that’s not really a problem as the thing I like the most about ADF is that its quite open for developers (for example Custom C#/.Net Activities) and it also offers a quite comprehensive REST API to control an manage it. For our monitoring purposes we are mainly interested in the LIST interface but we could do basically every operation using this API. In my example I only used the Dataset API, the Slices API and the Pipeline API.
First we start with the Dataset API to get a list of all data sets in our Data Factory. This is quite simple as we just need to build our URL of the REST web service like this:
You can get all of this information for the Azure Portal by simply navigating to your Data Factory and checking the URL which will be similar to this one:
So this would be my values for the API Call: – {SubscriptionID} would be “12345678-3232-4a04-a0a6-6e44bf2f5d11” – {ResourceGroupName} would be “myResourceGroup” – {DataFactoryName} would be “myDataFactory” – {api-version} would be a fixed value of “2015-10-01”
Once you have your URL you can use PowerBI to query the API using Get Data –> From Web Next you need to authenticate using your Personal or Organizational Account – the same that you use to sign in to the Portal – and also the level for which you want to use the credentials. I’d recommend you to set it either to the subscription level or to the data-factory itself, depending on your security requirements. This ensures that you are not asked for credentials for each different API:
This works in a very similar way also for the Slices API, the Pipeline API and all other APIs available! The other transformations I used are regular PowerQuery/M steps done via the UI so I am not going to describe them in more detail here. Also, setting up the relationships in our final PowerPivot model should be straight forward.
Now that we have all the required data in place, we can start with our report. I used some custom visuals for the calendar view, some slicers and a simple table to show the details. I also used a Sankey Chart to visualize the dependencies between the datasets.
Compared to the standard GUI for monitoring this provides a much better overview of slices and their current states and it also allows easy filtering. I am sure there are a lot of other PowerBI visualizations which would make a lot of sense here, these are just to give you an idea how it could look like, but of course you have all the freedom PowerBI offers you for reporting!
The only drawback at the moment is that you cannot reschedule/reset slices from PowerBI but for my monitoring-use-case this was not a problem at all. Also, I did not include the SliceRun API in my report as this would increase the size of the data model a lot, so detailed log information is not available in my sample report.
One of the most requested features when it comes to Azure ML is and has always been the integration into PowerBI. By now we are still lacking a native connector in PowerBI which would allow us to query a published Azure ML web service directly and score our datasets. Reason enough for me to dig into this issue and create some Power Query M scripts to do this. But lets first start off with the basics of Azure ML Web Services.
Every Azure ML project can be published as a Web Service with just a single click. Once its published, it can be used like any other Web Service. Usually we would send a record or a whole dataset to the Web Service, the Azure ML models does some scoring (or any other operation within Azure ML) and then sends the scored result back to the client. This is straight forward and Microsoft even supplies samples for the most common programming languages. The Web Service relies on a standardized REST API which can basically be called by any client. Yes, in our case this client will be PowerBI using Power Query. Rui Quintino has already written an article on AzureML Web Service Scoring with Excel and Power Query and also Chris Webb wrote a more generic one on POST Request in Power Query in general Web Service and POST requests in Power Query. Even Microsoft recently published an article how you can use the R Integration of Power Query to call a Azure ML Web Service here.
Having tried these solutions, I have to admit that they have some major issues: 1) very static / hard coded 2) complex to write 3) operate on row-by-row basis and might run into the API Call Limits as discussed here. 4) need a local R installation
As Azure ML usually deal with tables, which are basically Power Query DataSets, a requirement would be to directly use a Power Query DataSet. The DataSet has to be converted dynamically into the required JSON structure to be POSTed to Azure ML. The returned result, usually a table again, should be converted back to a Power Query DataSet. And that’s what I did, I wrote a function that does all this for you. All information that you have to supply can be found in the configuration of your Azure ML Web Service: – Request URI of your Web Service – API Key – the [Table to Score]
the [Table to Score] can be any Power Query table but of course has to have the very same structure (including column names and data types) as expected by the Web Service Input. Then you can simply call my function:
The whole process involves a lot of JSON conversions and is kind of complex but as I encapsulated everything into M functions it should be quite easy to use by simply calling the CallAzureMLService-function.
However, here is a little description of the used functions and the actual code:
ToAzureMLJson – converts any object that is passed in as an argument to a JSON element. If you pass in a table, it is converted to a JSON-array. Dates and Numbers are formatted correctly, etc. so the result can the be passed directly to Azure ML.
let
ToAzureMLJson= (input as any) as text =>
let
transformationList = {
[Type = type time, Transformation = (value_in as time) as text => """" & Time.ToText(value_in, "hh:mm:ss.sss") & """"],
[Type = type date, Transformation = (value_in as date) as text => """" & Date.ToText(value_in, "yyyy-MM-dd") & """"],
[Type = type datetime, Transformation = (value_in as datetime) as text => """" & DateTime.ToText(value_in, "yyyy-MM-ddThh:mm:ss.sss" & """")],
[Type = type datetimezone, Transformation = (value_in as datetimezone) as text => """" & DateTimeZone.ToText(value_in, "yyyy-MM-ddThh:mm:ss.sss") & """"],
[Type = type duration, Transformation = (value_in as duration) as text => ToAzureMLJson(Duration.TotalSeconds(value_in))],
[Type = type number, Transformation = (value_in as number) as text => Number.ToText(value_in, "G", "en-US")],
[Type = type logical, Transformation = (value_in as logical) as text => Logical.ToText(value_in)],
[Type = type text, Transformation = (value_in as text) as text => """" & value_in & """"],
[Type = type record, Transformation = (value_in as record) as text =>
let
GetFields = Record.FieldNames(value_in),
FieldsAsTable = Table.FromList(GetFields, Splitter.SplitByNothing(), {"FieldName"}, null, ExtraValues.Error),
AddFieldValue = Table.AddColumn(FieldsAsTable, "FieldValue", each Record.Field(value_in, [FieldName])),
AddJson = Table.AddColumn(AddFieldValue, "__JSON", each ToAzureMLJson([FieldValue])),
jsonOutput = "[" & Text.Combine(AddJson[__JSON], ",") & "]"
in
jsonOutput
],
[Type = type table, Transformation = (value_in as table) as text =>
let
BufferedInput = Table.Buffer(value_in),
GetColumnNames = Table.ColumnNames(BufferedInput),
ColumnNamesAsTable = Table.FromList(GetColumnNames , Splitter.SplitByNothing(), {"FieldName"}, null, ExtraValues.Error),
ColumnNamesJson = """ColumnNames"": [""" & Text.Combine(ColumnNamesAsTable[FieldName], """, """) & """]",
AddJson = Table.AddColumn(value_in, "__JSON", each ToAzureMLJson(_)),
ValuesJson = """Values"": [" & Text.Combine(AddJson[__JSON], ",#(lf)") & "]",
jsonOutput = "{""Inputs"": { ""input1"": {" & ColumnNamesJson & "," & ValuesJson & "} }, ""GlobalParameters"": {} }"
in
jsonOutput
],
[Type = type list, Transformation = (value_in as list) as text => ToAzureMLJson(Table.FromList(value_in, Splitter.SplitByNothing(), {"ListValue"}, null, ExtraValues.Error))],
[Type = type binary, Transformation = (value_in as binary) as text => """0x" & Binary.ToText(value_in, 1) & """"],
[Type = type any, Transformation = (value_in as any) as text => if value_in = null then "null" else """" & value_in & """"]
},
transformation = List.First(List.Select(transformationList , each Value.Is(input, _[Type]) or _[Type] = type any))[Transformation],
result = transformation(input)
in
result
in
ToAzureMLJson
AzureMLJsonToTable – converts the returned JSON back to a Power Query Table. It obeys column names and also data types as defined in the Azure ML Web Service output. If the output changes (e.g. new columns are added) this will be taken care of dynamically!
let
AzureMLJsonToTable = (azureMLResponse as binary) as any =>
let
WebResponseJson = Json.Document(azureMLResponse ,1252),
Results = WebResponseJson[Results],
output1 = Results[output1],
value = output1[value],
BufferedValues = Table.Buffer(Table.FromRows(value[Values])),
ColumnNameTable = Table.AddIndexColumn(Table.FromList(value[ColumnNames], Splitter.SplitByNothing(), {"NewColumnName"}, null, ExtraValues.Error), "Index", 0, 1),
ColumnNameTable_Values = Table.AddIndexColumn(Table.FromList(Table.ColumnNames(BufferedValues), null, {"ColumnName"}), "Index", 0, 1),
RenameList = Table.ToRows(Table.RemoveColumns(Table.Join(ColumnNameTable_Values, "Index", ColumnNameTable, "Index"),{"Index"})),
RenamedValues = Table.RenameColumns(BufferedValues, RenameList),
ColumnTypeTextTable = Table.AddIndexColumn(Table.FromList(value[ColumnTypes], Splitter.SplitByNothing(), {"NewColumnType_Text"}, null, ExtraValues.Error), "Index", 0, 1),
ColumnTypeText2Table = Table.AddColumn(ColumnTypeTextTable, "NewColumnType", each
if Text.Contains([NewColumnType_Text], "Int") then type number
else if Text.Contains([NewColumnType_Text], "DateTime") then type datetime
else if [NewColumnType_Text] = "String" then type text
else if [NewColumnType_Text] = "Boolean" then type logical
else if [NewColumnType_Text] = "Double" or [NewColumnType_Text] = "Single" then type number
else if [NewColumnType_Text] = "datetime" then type datetime
else if [NewColumnType_Text] = "DateTimeOffset" then type datetimezone
else type any),
ColumnTypeTable = Table.RemoveColumns(ColumnTypeText2Table ,{"NewColumnType_Text"}),
DatatypeList = Table.ToRows(Table.RemoveColumns(Table.Join(ColumnNameTable, "Index", ColumnTypeTable, "Index"),{"Index"})),
RetypedValues = Table.TransformColumnTypes(RenamedValues, DatatypeList, "en-US"),
output = RetypedValues
in
output
in
AzureMLJsonToTable
CallAzureMLService – uses the two function from above to convert a table to JSON, POST the JSON to Azure ML and convert the result back to a Power Query Table.
let
CallAzureMLService = (
WebServiceURI as text,
WebServiceKey as text,
TableToScore as table,
optional Timeout as number
) as any =>
let
WebTimeout = if Timeout = null then #duration(0,0,0,100) else #duration(0,0,0,Timeout) ,
WebServiceContent = ToAzureMLJson(TableToScore),
WebResponse = Web.Contents(WebServiceURI,
[Content = Text.ToBinary(WebServiceContent),
Headers = [Authorization="Bearer " & WebServiceKey,
#"Content-Type"="application/json",
Accept="application/json"],
Timeout = WebTimeout]),
output = AzureMLJsonToTable(WebResponse)
in
output
in
CallAzureMLService
Known Issues: As the [Table to Score] will probably come from a SQL DB or somewhere else, you may run into issues with Privacy Levels/Settings and the Formula Firewall. In this case make sure to enable Fast Combine for your workbook as described here.
The maximum timeout of a Request/Response call to an Azure ML Web Service is 100 seconds. If your call exceeds this limit, you might get an error message returned.I ran a test and tried to score 60k rows (with 2 numeric columns) at once and it worked just fine, but I would assume that you can run into some Azure ML limits here very easily with bigger data sets. As far as I know, these 100 seconds are for the Azure ML itself only. If it takes several minutes to upload your dataset in the POST request, than this is not part of this 100 seconds. If you are still hitting this issue, you could further try to split your table into different batches, score them separately and combine the results again afterwards.
So these are the steps that you need to do in order to use your Azure ML Web Service together with PowerBI: 1) Create an Azure ML Experiment (or use an existing) 2) Publish the Experiment as a Web Service 3) note the URL and the API Key of your Web Service 4) run PowerBI and load the data that you want to score 5) make sure that the dataset created in 4) has the exact same structure as expected by Azure ML (column names, data types, …) 6) call the function “CallAzureMLWebService” with the parameters from 3) and 5) 7) wait for the Web Service to return the result set 8) load the final table into PowerBI (or do some further transformations before)
And that’s it!
Download: You can find a PowerBI workbook which contains all the functions and code here: CallAzureMLWebService.pbix I used a simple Web Service which takes 2 numeric columns (“Number1” and “Number2”) and returns the [Number1] * [Number2] and [Number1] / [Number2]
PS: you will not be able to run the sample as it is as I changed the API Key and also the URL of my original Azure ML Web Service
One of the coolest features of Power BI is that I integrates very well with other tools and also offers a lot of interfaces which can be used to extend this capabilities even further. One of those is the R Integration which allows you to run R code from within Power BI. R scripts can either be used as a data source or for visualizing your data. In this post I will focus on the data source component and show how you can use a locally stored R script and execute it directly in Power BI. Compared to the native approach where you need to embed the R code in the Power BI file, this has several advantages:
Develop R script in familiar external tool like RStudio
Integration with Source Control
Leverage Power BI for publishing and visualizing results
Out of the box Power BI only supplies one function to call R scripts as a data source which is R.Execute(text). Usually, when you use the wizard, it simply passes your R script as a hardcoded value to this function. Knowing the power of Power BI and its scripting language M for data integration made me think – “Hey, as R scripts are just text files and Power BI can read text files, I could also dynamically read any R script and execute it!”
Well, turns out to be true! So I created a little M function where I pass in the file-path of an existing R script and which returns a table of data frames which are created during the execution of the script. Those can then be used like any other data sets/tables within Power BI:
And here is the corresponding M code for the Power Query function: (Thanks also to Imke Feldmann for simplifying my original code to the readable one below)
let
LoadLocalRScript = (file_path as text) as table =>
First we read the R script like any other regular CSV file but we use line-feed (“#(lf)”) as delimiter. So we get a table with one column and one row for each line of our original R script. Then we use Text.Combine() on our column to transform the single lines back into one long text resembling our original R script. This text can the be passed to the R.Execute() function to return the list of R data frames created during the execution of the script.
And that’s it! Any further steps are similar to using any regular R script which is embedded in Power BI so it is up to you on how you proceed from here. Just one thing you need to keep in mind is that changing the local R script might break the Power BI load if you changed or deleted any data frames which are referenced in Power BI later on.
One issues that I came across during my tests is that this approach does not work with scheduled refreshes in the Power BI Web Service via the Personal Gateway. The first reason for this is that it is currently not possible to use scheduled refresh if custom functions are involved. Even if you can work around this issue pretty easily by using the code from above directly in Power Query I still ran into issues with different privacy levels for the location of the R script and the R.Execute() function. But I will investigate into those issues and update this blog post accordingly (see UPDATE below). For the future I hope that is fixed by Microsoft and Power BI allows you to execute remote scripts natively – but until then, this approach worked quite well for me.
UPDATE: To make the refresh via the Personal Gateway work you have to enable “FastCombine”. How to do this is described in more detail here: Turn on FastCombine for Personal Gateway.
In case you are interested in more details on this approach, I am speaking at TugaIT in Lisbon, Portugal this Friday (20th of May 2016) about “Power BI for the Data Scientist” where I will cover this and lots of other interesting topics about the daily work of a data scientist and how PowerBI can used to ease them.
UPDATE: This does not work for Tabular Models in Compatibility Level 120 or above as they do not expose the calculation dependencies anymore!
One of my best practices when designing bigger SQL Server Analysis Services (SSAS) Tabular models is to nest calculations whenever possible. The reasons for this should be quite obvious:
no duplication of logics
easier to develop and maintain
(caching)
However, this also comes with a slight drawback: after having created multiple layers of nested calculations it can be quite hart to tell on which measures a top-level calculations actually depends on. Fortunately the SSAS engine exposes this calculation dependencies in one of its DMVs – DISCOVER_CALC_DEPENDENCY. This DMV basically contains information about all calculations in the model:
Calculated Measures
Calculated Columns
Relationships
Dependencies to Tables/Columns
Chris Webb already blogged about this DMV some time ago and showed some basic (tabular) visualization within an Excel Pivot table (here). My post focuses on PowerBI and how can make the content of this DMV much more appealing and visualize it in a way that is very easy to understand. As the DMV is built up like a parent-child hierarchy, I had to use a recursive M-function to resolve this self-referencing table which actually was the hardest part to do. Each row contains a link to a dependent object, which can have other dependencies again. In order to visualize this properly and let the user select a Calculation of his choice to see a calculation tree, I needed to expand each row with all of its dependencies, keeping their link to the root-node:
Here is a little example:
Object
Referenced_Object
A
B
B
C
The table above is resolved to this table:
Root
Object
Referenced_Object
A
A
B
A
B
C
B
B
C
The Root-column is then used to filter and get all dependent calculations. The PowerBI file also contains some other M-functions but those are mainly for ease-of-use and to keep the queries simple.
You can use the Slicers to filter on the Table, the Calculation Type and the Calculation itself and the visual shows all the dependencies down to the physical objects being Tables and Columns. This makes it a lot easier to understand your model and the dependencies that you built up over time. I attached the sample-PowerBI-file below. You simply need to change the connectionstring to your SSAS Tabular Server and refresh the data connections.
Since the last major update last year, Power BI offers some APIs which can be used to interact with content and also data that is stored in Power BI. Microsoft provides a good set of samples on how to use the APIs on GitHub and also a an interactive APIARY web-UI which you can use to build and test API calls on-the-fly. However, it can still be quite cumbersome as you have to deal with all the REST API calls and the returned JSON on your own. So I decided to write a little C# Wrapper where you simply pass in your Azure AD Application Client ID and you can deal with all Object of the Power BI API as they were regular C# objects.
Here is a little example on how to list all available reports and get the EmbedURL of a given tile using the PowerBIClient:
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using pmOne.PowerBI; using pmOne.PowerBI.PowerBIObjects;
Console.WriteLine(“Press <Enter> to exit …”); Console.ReadLine(); } } }
As you can see, its pretty simple and very easy to use, even for non-developers. You can find all the source-code and the sample application for download below. The code as I have written it is very likely not the best code possible, but it works for my needs, is straight forward, simple and saves me a lot of work and time when dealing with the PowerBI API. Also, if the API changes, you may need to adopt the code accordingly. However, for the future I hope that Microsoft provides some metadata so that VisualStudio can build all this code automatically using e.g. Swagger. But for the time being feel free to use, improve or extend my code
The original request for this calculation came from one of my blog readers who dropped me a mail asking if it possible to calculated the Pearson Correlation Coefficient (PCC or PPMCC) in his PowerPivot model. In case you wonder what the Pearson Correlation Coefficient is and how it can be calculated – as I did in the beginning – these links What is PCC, How to calculate PCC are very helpful and also offer some examples and videos explaining everything you need to know about it. I highly recommend to read the articles before you proceed here as I will not go into the mathematical details of the calculation again in this blog which is dedicated to the DAX implementation of the PCC.
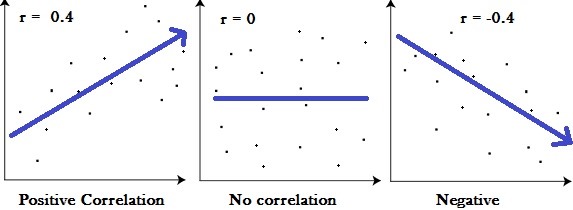
Anyway, as I know your time is precious, I will try to sum up its purpose for you: “The Pearson Correlation Coefficient calculates the correlation between two variables over a given set of items. The result is a number between -1 and 1. A value higher than 0.5 (or lower than –0.5) indicate a strong relationship whereas numbers towards 0 imply weak to no relationship.”
The two values we want to correlate are our axes, whereas the single dots represent our set of items. The PCC calculates the trend within this chart represented as an arrow above.
The mathematical formula that defines the Pearson Correlation Coefficient is the following:
The PCC can be used to calculate the correlation between two measures which can be associated with the same customer. A measure can be anything here, the age of a customer, it’s sales, the number of visits, etc. but also things like sales with red products vs. sales with blue products. As you can imagine, this can be a very powerful statistical KPI for any analytical data model. To demonstrate the calculation we will try to correlate the order quantity of a customer with it’s sales amount. The order quantity will be our [MeasureX] and the sales will be our [MeasureY], and the set that we will calculate the PCC over are our customers. To make the whole calculation more I split it up into separate measures:
MeasureX := SUM(‘Internet Sales’[Order Quantity])
MeasureY := SUM(‘Internet Sales’[Sales Amount])
Based on these measures we can define further measures which are necessary for the calculation of our PCC. The calculations are tied to a set if items, in our case the single customers:
Now that we have calculated the various summations over our base measures, it is time to create the numerator and denominator for our final calculation:
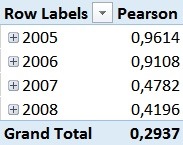
This [Pearson]-measure can then be used together with any attribute in our model – e.g. the Calendar Year in order to track the changes of the Pearson Correlation Coefficient over years:
Pearson by Year
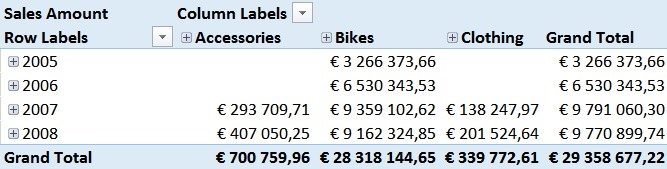
For those of you who are familiar with the Adventure Works sample DB, this numbers should not be surprising. In 2005 and 2006 the Adventure Works company only sold bikes and usually a customer only buys one bike – so we have a pretty strong correlation here. However, in 2007 they also started selling Clothing and Accessories which are in general cheaper than Bikes but are sold more often.
Pearson by Year and Category
This has impact on our Pearson-value which is very obvious in the screenshots above.
As you probably also realized, the Grand Total of our Pearson calculation cannot be directly related to the single years and may also be the complete opposite of the single values. This effect is called Simpson’s Paradox and is the expected behavior here.
[MeasuresX] and [MeasureY] can be exchanged by any other DAX measures which makes this calculation really powerful. Also, the set of items over which we want to calculated the correlation can be exchanged quite easily. Below you can download the sample Excel workbook but also a DAX query which could be used in Reporting Services or any other tool that allows execution of DAX queries.
I am very glad that I got selected as a speaker for two upcoming SQL Saturdays in June. First there is the SQL Saturday #409 in Rheinland, Germany on June 13 and the week after the SQL Saturday #419 in Bratislava, Slovakia on June 20.
For those of you who are new to the concept of PASS SQL Saturdays, this is a series of free-of-charge events all around the globe where experienced speakers talk about all topics around the Microsoft SQL Server platform and beyond. As I said, its free, you just need to register in time in order to get a ticked so better be fast before all slots are taken!
I will do a session together with my colleague Markus Begerow (b, t) on “Power BI on SAP HANA” – two technologies I got to work a lot with recently. We are going to share our experience on how to use Power BI to extract data from SAP HANA, the different interfaces you can use and the advantages and drawbacks of each. Even tough it is considered a general sessions, we will also do a lot of hands on and elaborate on some of the technical details you need to be aware of, for both, the Power BI side and also for SAP HANA.
In Bratislava I will speak about Lessons Learned: SSAS Tabular in the real world where I will present the technical and non-technical findings I made in the past when implementing SSAS Tabular models at larger scales for various customers. I will cover the whole process from choosing SSAS Tabular as your engine (or not choosing it), things to consider during implementation and also shed some light on the administrative challenges once the solution is in production.
I think both are really interesting sessions and I would be happy to see a lot of you there and have some interesting discussions!
If you have ever tried to implement a recursive calculations in DAX similar to how you would have done it back in the good old days of MDX (see here) you would probably have come up with a DAX formula similar to the one below:
Sales ForeCast :=
IF (
NOT( ISBLANK( [Sales] )),
[Sales],
CALCULATE(
[Sales ForeCast],
DATEADD('Date'[Calendar],–1,MONTH)
)* 1.05
)
However, in DAX you would end up with the following error:
A circular dependency was detected: ‘Sales'[Sales ForeCast],’Sales'[Sales ForeCast].
This makes sense as you cannot reference a variable within its own definition – e.g. X = X + 1 cannot be defined from a mathematical point of view (at least according to my limited math skills). MDX is somehow special here where the SSAS engine takes care of this recursion by taking the IF() into account.
So where could you possible need a recursive calculation like this? In my example I will do some very basic forecasting based on monthly growth rates. I have a table with my actual sales and another table for my expected monthly growth as percentages. If I do not have any actual sales I want to use my expected monthly growth to calculate my forecast starting with my last actual sales:
This is a very common requirement for finance applications, its is very easy to achieve in pure Excel but very though to do in DAX as you probably realized on your own what finally led you here
In Excel we would simply add a calculation like this and propagate it down to all rows: (assuming column C contains your Sales, D your Planned Growth Rate and M is the column where the formula itself resides)
In order to solve this in DAX we have to completely rewrite our calculation! The general approach that we are going to use was already explained by Mosha Pasumansky some years back, but for MDX. So I adopted the logic and changed it accordingly to also work with DAX. I split down the solution into several steps: 1) find the last actual sales – April 2015 with a value of 35 2) find out with which value we have to multiply our previous months value to get the current month’s Forecast 3) calculate the natural logarithm (DAX LN()-function) of the value in step 2) 4) Sum all values from the beginning of time until the current month 5) Raise our sum-value from step 4) to the power of [e] using DAX EXP()-function 6) do some cosmetic and display our new value if no actual sales exist and take care of aggregation into higher levels
Note: The new Office 2016 Preview introduces a couple of new DAX functions, including PRODUCTX() which can be used to combine the Steps 3) to 5) into one simple formula without using any complex LN() and EXP() combinations.
Step 1: We can use this formula to get our last sales:
Last Sales :=
IF (
ISBLANK(
CALCULATE(
[Sales],
DATEADD('Date'[DateValue], 1,MONTH)
)
),
[Sales],
1
)
It basically checks if there are no [Sales] next month. If yes, we use the current [Sales]-value as our [Last Sales], otherwise we use a fixed value of 1 as a multiplication with 1 has no impact on the final result.
Step 2: Get our multiplier for each month:
MultiplyBy :=
IF (
ISBLANK( [Last Sales] ),
1 + [Planned GrowthRate],
[Last Sales]
)
If we do not have any [Last Sales], we use our [Planned GrowthRate] to for our later multiplication/summation, otherwise take our [Last Sales]-value.
Step 3 and 4: As we cannot use “Multiply” as our aggregation we first need to calculate the LN and sum it up from the first month to the current month:
Step 5 and 6: If there are no actual sales, we display our calculated Forecast:
Sales ForeCast :=
SUMX(
VALUES ('Date'[Month] ),
IF ( ISBLANK( [Sales] ),EXP( [Cumulated LN] ), [Sales] )
)
Note that we need to use SUMX over our Months here in order to also get correct subtotals on higher levels, e.g. Years. That’s all the SUMX is necessary for, the IF itself should be self-explaining here.
So here is the final result – check out the last column:
The calculation is flexible enough to handle missing sales. So if for example we would only have sales for January, our recursion would start there and use the [Planned GrowthRate] already to calculate the February Forecast-value:
Two weeks ago at the German SQL Server Conference 2015 I was at Peter Myer’s session about Mastering the CUBE Functions in Excel. (PS: Peter is also speaking on our upcoming SQLSaturday #374 in Vienna next week and at PASS SQLRally in Copenhagen the week after). After his session we had a further discussion about this topic and our experiences on how to use Excels CUBE-functions in order to build nice Dashboards with native Excel functionalities that also work with e.g. Excel Services. Its always great to exchange with people that share the same passion on he same topic! One thing we both agreed on that is missing currently is a way to get the MDX UniqueName of something that is selected in a slicer, filter or simply in a cell using CUBEMEMBER-function. I once used a special Cube Measure which was created in MDX Script which returned the UniqueName of a given member that was selected together with this special measure. For this to work with Excel you need to know how Excel builds the MDX when querying cube values using CUBEVALUE-function. Here is a little example: This produces the following MDX query:
So it basically creates a tuple that contains everything you pass into the CUBEVALUE-Function as a parameter. Knowing this we can create a calculated measure to get the MDX UniqueName of this tuple using MDX StrToTuple()- and MDX AXIS()-function:
MEMBER [Measures].[Excel TupleToStr] AS (
TupleToStr(axis(0).item(0))
)
Replacing the [Measures].[Internet Sales Amount] of our initial CUBEVALUE-function with this new measure would return this to Excel:
Ok, so far so good but nothing really useful as you need to hardcode the member’s UniqueName into the CUBEVALUE-function anyway so you already know the UniqueName. However, this is not the case if you are dealing with Pivot Table Page Filters and/or Slicers! You can simply refer to them within the CUBEVALUE-function but you never get the UniqueName of the selected item(s). Well, at least not directly! But you can use the approach described above, using an special MDX calculated measure, to achieve this as I will demonstrate on the next pages.
Calculated measures can only be created using the Pivot Table interface but can also be used in CUBE-functions. So first thing you need to do is to create a Pivot Table and add a new MDX Calculated Measure:
!Caution! some weird MDX coming !Caution!
You may wonder, why such a complex MDX is necessary and what it actually does. What it does is the following: Based on the example MDX query that Excel generates (as shown above) this is a universal MDX that returns the MDX UniqueName of any other member that is selected together with our measure using the CUBEVALUE-function. It also removes the UniqueName of the measure itself so the result can be used again with any other measure, e.g. [Internet Sales Amount] The reason why it is rather complex is that Excel may group similar queries and execute them as a batch/as one query to avoid too many executions which would slow down the overall performance. So we cannot just reference the first element of our query as it may belong to any other CUBEVALUE-function. This MDX deals with all this kinds of issues.
The MDX above allows you to specify only two additional filters but it may be extended to any number of filters that you pass in to the CUBEMEMBER-function. This would be the general pattern:
After creating this measure we can now use it in our CUBE-functions in combination with our filters and slicers:
You may noted that I had to use CUBERANKEDMEMBER here. This is because filters and slicers always return a set and if we would pass in a set to our CUBEVALUE function a different MDX query would be generated which would not allow us to extract the single UniqueNames of the selected items using the approach above (or any other MDX I could think of). So, this approach currently only works with single selections! I hope that the Excel team will implement a native function to extract the UniqueName(s) of the selected items in the future to make this workaround obsolete!
Once we have our UniqeName(s) we can now use them in e.g. a CUBESET-function to return the Top 10 days for a given group of product (filter) and the selected year (slicer):
And that’s it!
So why is this so cool?
It works with SSAS (multidimensional and tabular) and Power Pivot as Excel still uses MDX to query all those sources. It may also work with SAP HANA’s ODBO connector but I have not tested this yet!
It does not require any VBA which would not work in Excel Services – this solution does!
The calculation is stored within the Excel Workbook so it can be easily shared with other users!
There is no native Excel functionality which would allow you to create a simple Top 10 report which works with filters and slicers as shown above or any more complex dynamic report/dashboard with any dynamic filtering.
So no more to say here – Have fun creating your interactive Excel web dashboards!
Note: You may also rewrite any TOPCOUNT expression and use the 4th and 5h parameter of the CUBESET-function instead. This is more native and does not require as much MDX knowledge: However, if you are not familiar with MDX, I highly recommend to learn it before you write any advanced calculations as show above as otherwise the results might be a bit confusing in the beginning! Especially if you filter and use TOPCOUNT on the same dimension!