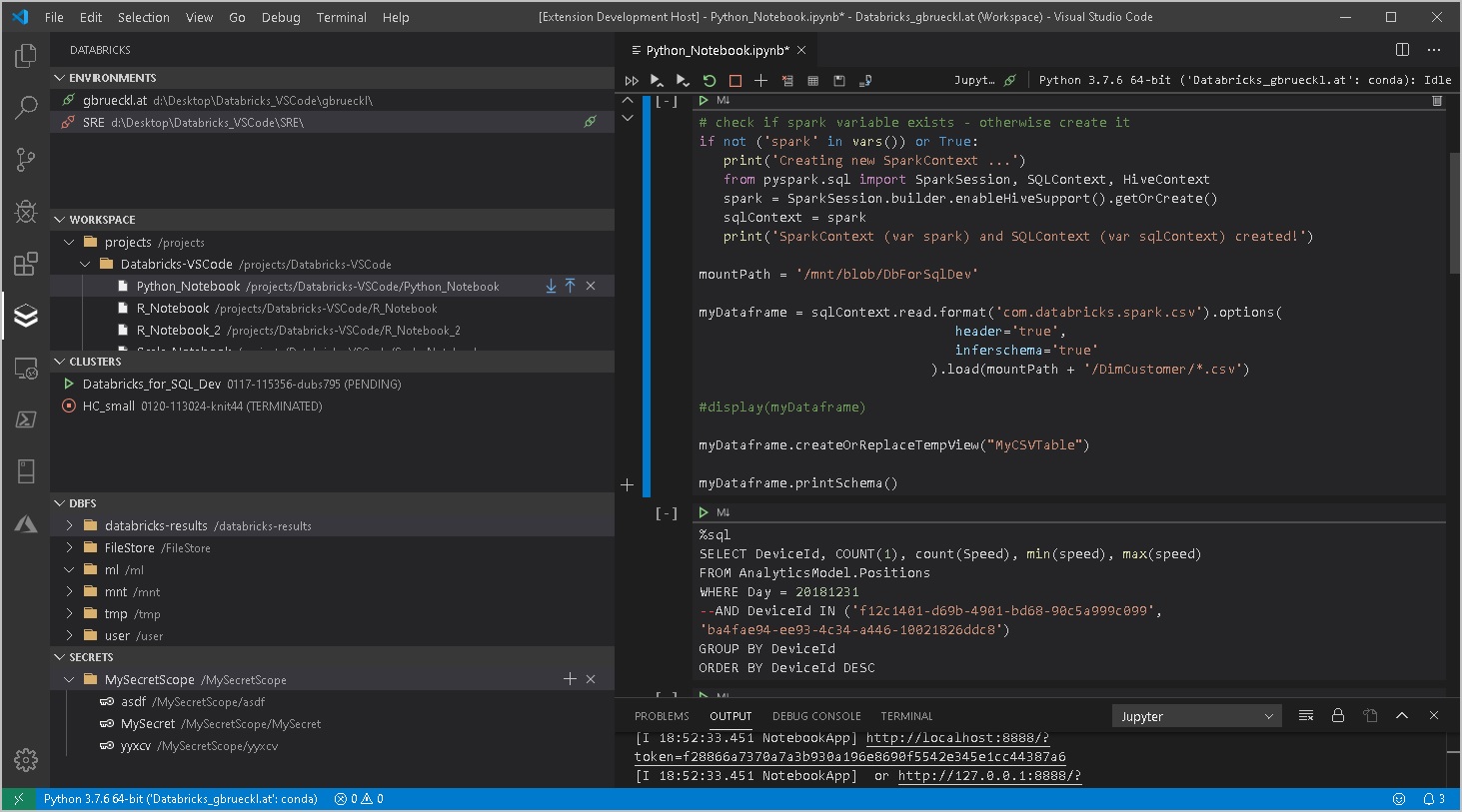
When working with Databricks you will usually start developing your code in the notebook-style UI that comes natively with Databricks. This is perfectly fine for most of the use cases but sometimes it is just not enough. Especially nowadays, where a lot of data engineers and scientists have a strong background also in regular software development and expect the same features that they are used to from their original Integrated Development Environments (IDE) also in Databricks.
For those users Databricks has developed Databricks Connect (Azure docs) which allows you to work with your local IDE of choice (Jupyter, PyCharm, RStudio, IntelliJ, Eclipse or Visual Studio Code) but execute the code on a Databricks cluster. This is awesome and provides a lot of advantages compared to the standard notebook UI. The two most important ones are probably the proper integration into source control / git and the ability to extend your IDE with tools like automatic formatters, linters, custom syntax highlighting, …
While Databricks Connect solves the problem of local execution and debugging, there was still a gap when it came to pushing your local changes back to Databricks to be executed as part of a regular ETL or ML pipeline. So far you had to either “deploy” your changes by manually uploading them via the Databricks UI again or write a script that uploads it via the REST API (Azure docs).
NOTE: I also published a PowerShell module that eases the automation/scripting of these tasks also as part of CI/CD pipeline. It is available from the PowerShell gallery DatabricksPS and integrates very well with this VSCode extension too!
However, this is not really something you would call a “seamless experience” so I also started working on an extension for Visual Studio Code to work more efficiently with Databricks. It has been in the VS Code gallery (Databricks VSCode) for about a month now and I received mostly positive feedback so far. Now I am at a stage where I want to get more people to use it – hence this blog post to announce it officially. The extension is currently published under GPLv3 license and is free to use for everyone. The GIT repository is also linked in the VS Code gallery if you want to participate or have any issues with the extension.

It currently supports the following features:
- Workspace browser
- Up-/download of notebooks and whole folders
- Compare/Diff of local vs online notebook (currently only supported for raw files but not for notebooks)
- Execution of local code and notebooks against a Databricks Cluster (via Databricks-Connect)
- Cluster manager
- Start/stop clusters
- Script cluster definition as JSON
- Job browser
- Start/stop jobs
- View job-run history + status
- Script job definition as JSON
- Script job-run output as JSON
- DBFS browser
- Upload files
- Download files
- (also works with mount points!)
- Secrets browser
- Create/delete secret scopes
- Create/delete secrets
- Support for multiple Databricks workspaces (e.g. DEV/TEST/PROD)
- Easy configuration via standard VS Code settings
More features to come in the future but these will be mainly based on the requests that come from users or my personal needs. So your feedback is highly appreciated – either directly here or using the feedback section in the GIT repository.
I will also write some follow up post to show you how to work in the most efficient way using this new VSCode extension in combination with your Databricks workspace so stay tuned!
VS Code gallery: paiqo.Databricks-VSCode
Github repository: Databricks-VSCode